
Instacart's Griffin 2.0: The ML Platform Behind the AI
Instacart's ML team published a detailed breakdown of Griffin 2.0 in November 2023, their next-generation machine learning platform. While it's not a text-to-SQL tool like Uber's QueryGPT or Pinterest's Querybook implementation, the lessons are directly relevant to anyone building AI-powered data applications.
Because before you can build an AI data agent, you need infrastructure that doesn't fight you.
The Griffin 1.0 Problem
Instacart's first ML platform worked. It had:
- Containerized environments for consistent builds
- CLI tools for the full development-to-production lifecycle
- A Feature Marketplace for sharing and versioning features
- Real-time inference on AWS ECS
On paper, everything you need. In practice, it created a series of problems that will sound familiar to any data or ML team.
The learning curve was brutal. MLEs took "several days to weeks" to become proficient in the command-line tools. Even with documentation and training sessions. Deployment required infrastructure knowledge. To launch an inference service, engineers needed to understand AWS ECS configuration. That's not domain knowledge for data scientists. Everything lived in GitHub PRs. Creating a new project? PR. Indexing features? PR. Setting up workflows? PR. Deploying? PR. It worked, but it created friction at every step. No unified view. Integration with multiple third-party tools meant MLEs had to jump between platforms to get a complete picture of their workloads.Sound familiar? These are the same problems that plague data tools everywhere. Technical capability isn't enough. Usability determines adoption.
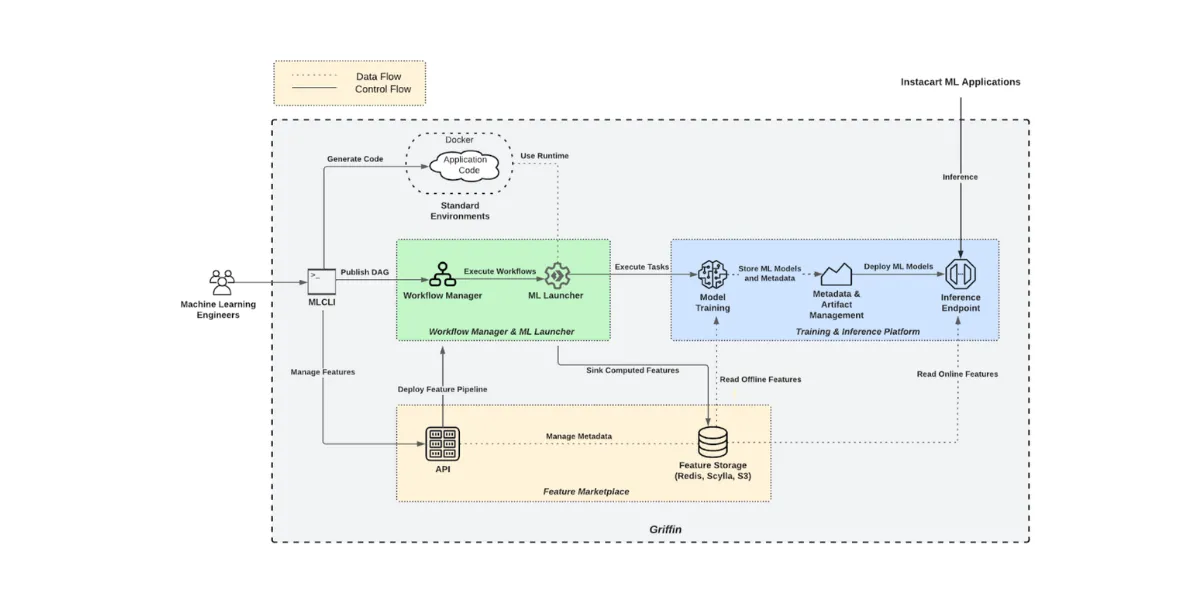
The Griffin 2.0 Philosophy
Instacart's redesign centered on four principles:
1. User-friendly interface over CLIs. Every operation—feature creation, training jobs, workflow monitoring, deployment—accessible through a web UI with just a few clicks. 2. Unified platform. All tools consolidated into one place. Including integration with external systems like Datadog, MLFlow, and ECS, all accessible through the same interface. 3. Centralized metadata. A data store tracking the entire ML lifecycle: features, training runs, model registry, lineage from training to serving. 4. Infrastructure for the future. Distributed computation supporting distributed training, LLM fine-tuning, and whatever comes next.The shift from "works technically" to "works for users" is the theme connecting Griffin 2.0 to every successful AI data tool we've covered.
The results speak for themselves: after launching Griffin 2.0, Instacart tripled the number of ML applications running in production within a year. Better UX didn't just make engineers happier; it unlocked business value that was previously stuck in development hell.
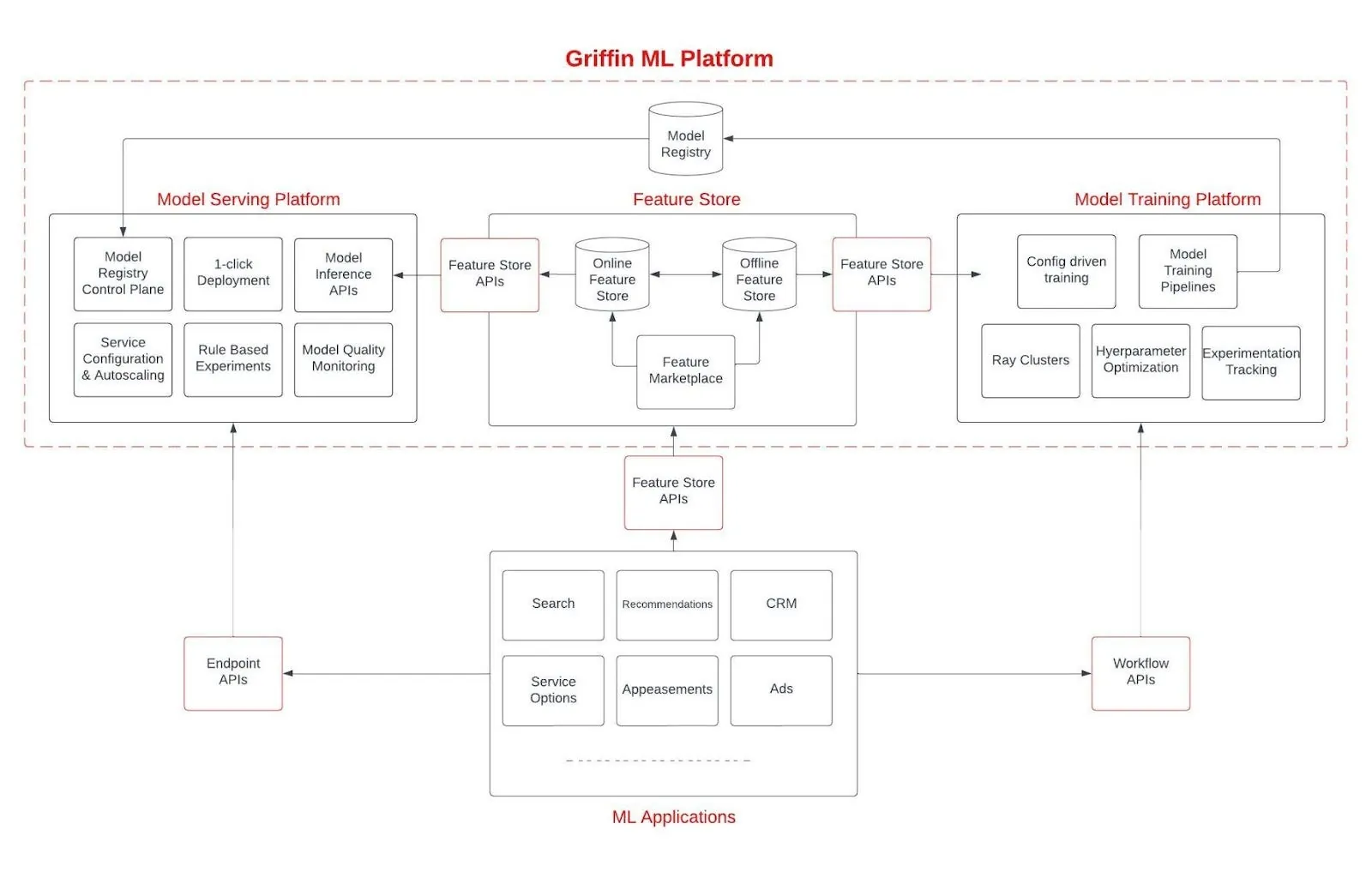
The Architecture That Enables AI
Griffin 2.0's building blocks are worth understanding:
ML Training Platform. Built on Ray for horizontally-scaled distributed training. Each workflow runs in its own Kubernetes namespace with unique service accounts, enabling true isolation between experiments. Provides configuration-based runtimes for TensorFlow and LightGBM so engineers don't have to worry about library conflicts. The Ray integration enables horizontal scaling across hundreds of cores for large training jobs. ML Serving Platform. A model registry for artifacts, a control plane for deployment, a proxy for experiments between model versions, and workers for feature retrieval, preprocessing, and inference. All automated and configurable through the UI. Feature Marketplace. Feature computation, ingestion, discovery, access, and sharing. With data validation to catch errors in feature generation early, and intelligent storage optimization for low-latency access. Centralized Metadata. This is the quiet hero. Griffin 1.0's CLI tools were "fire-and-forget"—hard to retrieve metadata later, difficult to manage training-serving lineage. Griffin 2.0 tracks everything, making the full lifecycle visible and manageable.Why This Matters for Data Agents
If you're building AI-powered data tools, you'll eventually hit these same problems:
Feature management. Text-to-SQL agents need context about tables, columns, business terms. That's feature engineering for LLMs. Pinterest's vector embeddings of table summaries, OpenAI's 6-layer context system, Vercel's semantic layer—these are all feature stores by another name. Experiment tracking. When you're iterating on prompts, retrieval strategies, and model choices, you need to track what worked. LinkedIn's SQL Bot team ran extensive A/B tests. Salesforce measures first-shot acceptance rates. Without infrastructure to capture this, you're flying blind. Deployment automation. Getting a model into production shouldn't require infrastructure expertise. Instacart's "few clicks to deploy" goal is the same as what DoorDash built with their AI platform: reduce the friction between experiment and production. Lineage and observability. When something breaks in production, you need to trace back to what changed. What data did the model see? What version was deployed? Griffin 2.0's centralized metadata makes this possible.The Adoption Lesson
The most important insight from Griffin 2.0 isn't technical—it's organizational:
"Despite extensive documentation and interactive training sessions, MLEs took several days to weeks to become proficient in using the in-house command-line tools."
Documentation doesn't fix bad UX. Training doesn't fix bad UX. Only better UX fixes bad UX.
Salesforce learned this with Horizon Agent—the Streamlit prototype worked but wasn't adopted until they moved to Slack. Pinterest built their text-to-SQL into Querybook where users already worked. LinkedIn's SQL Bot lives in their existing analytics workflow.
The pattern is universal: meet users where they are, with interfaces that match how they think.
The LLM-Ready Foundation
One detail from Instacart's post hints at where they're headed:
"The guiding principles behind Griffin 2.0—including centralized feature and metadata management, distributed computation capabilities, and standardized, optimized serving mechanisms—ensure that our ML infrastructure is well-prepared for advanced applications like LLM training, fine-tuning, and serving in the future."
This is infrastructure designed to scale. The same platform that trains recommendation models can fine-tune LLMs. The same feature store that serves traditional ML can power RAG systems. The same serving infrastructure that handles predictions can handle LLM inference.
Companies that invest in this foundation now will move faster when the next capability emerges.
Key Takeaways
1. Usability trumps capability. A powerful system nobody uses is worthless. Invest in UX. 2. Consolidate into one place. Jumping between tools creates friction and loses context. Unified platforms win. 3. Track everything. Metadata, lineage, experiments. When you need to debug production, you'll be glad you did. 4. Build for what's next. Distributed training, LLM fine-tuning, real-time serving—the infrastructure you build today determines what you can ship tomorrow. 5. Measure adoption, not just performance. How long does it take a new engineer to ship their first model? That's the metric that matters.The AI revolution isn't just about models. It's about the infrastructure that makes models usable.
Related reading:- DoorDash's AI Platform: 4 Stages of Evolution
- Airbnb's AI Platform: 13 Models with Guardrails
- OpenAI's Data Agent: Lessons from 600PB Scale
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.