
d0: What Vercel's AI Data Agent Teaches Us About the Future of Analytics (2025)
"Our d0 agent has completely changed the way I work. I can't imagine doing my job without this capability."
That's Guillermo Rauch, CEO of Vercel, talking about an internal AI agent that lets anyone at the company ask data questions in Slack. But the fascinating part isn't what d0 does. It's how they made it work.
They deleted 80% of their tools. And performance went through the roof.
What is d0?
If v0 is Vercel's AI for building UI, d0 is their AI for understanding data.
d0 lives in Slack. Anyone at Vercel can ask it questions like:
"Hey @d0 tell me the Vercel regions with most Function invocations?"
"@d0, how many users opted into the new dashboard experience and stayed opted-in?"
"@d0 how many vercel team internal projects were vulnerable a week ago to react2shell?"
And it returns answers, with the SQL to back them up:
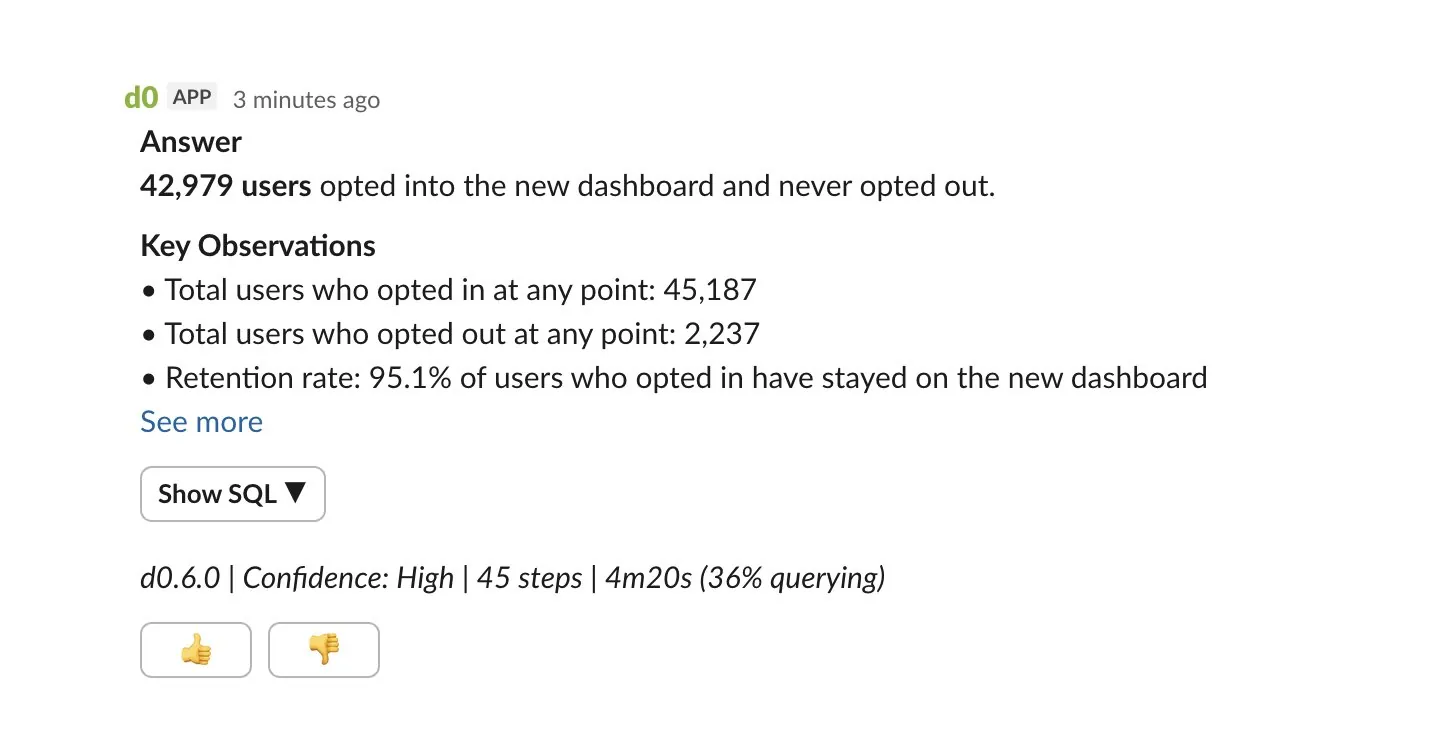
No waiting for the data team. No learning a BI tool. Just ask.
Rauchg's enthusiasm is telling: "We tried for years to get the 'Jarvis of data' working. Opus 4.5 + Sandbox + Gateway has made it possible. There's no going back."
This is the promise we've all heard about AI and data: natural language to insights. But the implementation details are what make d0 interesting.
The Original Architecture (That Didn't Work)
Vercel's team spent months building d0 the way most of us would. They created specialized tools for every task the agent might need:
- A tool to list database tables
- A tool to get column information
- A tool to write SQL queries
- A tool to validate queries
- A tool to execute queries
- Tools for specific query patterns
- Tools for error handling
Eleven tools in total. Each one carefully designed. Heavy prompt engineering. Careful context management.
It worked... kind of.
80% success rate. Which sounds okay until you realize that means one in five questions failed. For a tool meant to replace asking the data team, that's not good enough.
The agent was slow. It used lots of tokens. It required constant maintenance. When something broke, debugging meant tracing through a maze of specialized tools and handoffs.
The Counterintuitive Fix
The breakthrough came from an unlikely source. Drew Bredvick (@DBredvick), an engineer at Vercel, had been building their AI SDR agent using a radically simple approach: just give the agent a filesystem and bash.
Andrew Qu saw Drew's results and decided to try the same pattern with d0. As he posted on X:
"After hearing about @DBredvick's success with building an agent that just has a filesystem, I rewrote d0, our internal data analyst agent, with a similar pattern. The improvements from the rewrite are night and day!"
The new architecture has essentially two capabilities:
- Read and write files
- Execute bash commands
That's it.
The agent now explores Vercel's semantic layer the way a human analyst would. It runs ls to see what files exist. It uses grep to find relevant definitions. It cats files to read dimension and metric definitions. Then it writes SQL based on what it discovered.
The results:
Metric | Before | After ----------------|----------|---------------- Success rate | 80% | 100% Speed | Baseline | 3.5x faster Token usage | Baseline | 37% fewer Steps per query | Baseline | 40% fewer
Not marginal improvements. A fundamental leap.
Why Does Removing Tools Make Things Better?
This seems backwards. More capability should mean better results, right?
Vercel's team explained it clearly:
"We were doing the model's thinking for it."
When you build a specialized tool for "get table information," you're telling the agent: "When you need schema info, use this black box." The agent becomes a router, deciding which tool to call next.
But modern LLMs (Claude, in Vercel's case) are remarkably good at reasoning. They've been trained on millions of examples of developers navigating codebases, grepping through files, piecing together understanding from scattered documentation.
By giving the agent filesystem access instead of specialized tools, Vercel let the model use skills it already had. The agent isn't routing between tools anymore. It's thinking about how to answer the question.
The Semantic Layer: The Unsung Hero
There's a critical piece that makes this work: Vercel's semantic layer.
Their data definitions aren't locked in a database or BI tool. They're YAML files in a repository that the agent can browse like any codebase.
The File Structure
src/semantic/
├── catalog.yml # Index of all entities
└── entities/
├── Company.yml # Company entity definition
├── People.yml # People/employees entity
└── Accounts.yml # Customer accounts entity
The Catalog: What Exists?
The catalog.yml file is the entry point, a registry of all available entities:
entities:
- name: Company
grain: one row per company record
description: >-
Company information including industry classification,
size metrics, and location data for analyzing business
demographics and organizational characteristics.
fields: ['id', 'name', 'industry', 'employee_count',
'revenue', 'founded_year', 'country', 'city']
example_questions:
- How many companies are in each industry?
- What is the average revenue by industry?
- Which companies have the most employees?
use_cases: >-
Market segmentation and industry analysis
Company size and revenue distribution reporting
- name: Accounts
grain: one row per customer account record
description: >-
Customer account records with contract details, revenue
metrics, and relationship information.
fields: ['id', 'account_number', 'company_id', 'status',
'account_type', 'monthly_value', 'total_revenue']
example_questions:
- What is the total monthly recurring revenue?
- How many accounts are Active vs Inactive?
- Which account managers manage the most accounts?
Notice the example_questions. This is genius: the agent can grep for keywords from the user's question to find relevant entities. Netflix's LORE uses similar semantic layer principles for explainability.
Entity Definitions: The Real Detail
Each entity file contains everything the agent needs to write SQL:
# entities/Company.yml
name: Company
type: fact_table
table: main.companies
grain: one row per company
description: Company information including industry, size, and location
dimensions:
- name: industry
sql: industry
type: string
description: Industry sector
sample_values: [Technology, Finance, Healthcare, Retail]
- name: employee_count
sql: employee_count
type: number
description: Number of employees
- name: revenue
sql: revenue
type: number
description: Annual revenue in USD
measures:
- name: total_revenue
sql: revenue
type: sum
description: Total revenue across companies
- name: avg_employees
sql: employee_count
type: avg
description: Average number of employees per company
joins:
- target_entity: People
relationship: one_to_many
join_columns:
from: id
to: company_id
- target_entity: Accounts
relationship: one_to_many
join_columns:
from: id
to: company_id
This is similar to LookML or dbt's semantic layer, but stored as plain files the agent can read.
How the Agent Uses This
When someone asks "What's the average revenue by industry?", the agent:
- Finds relevant entities: grep -r "revenue" catalog.yml → finds Company entity
- Reads the entity definition: cat entities/Company.yml
- Discovers the schema: sees revenue dimension, industry dimension, main.companies table
- Understands relationships: sees joins to People and Accounts if needed
- Writes SQL: SELECT industry, AVG(revenue) FROM main.companies GROUP BY industry
The key insight from Vercel's blog: "LLMs have been trained on massive amounts of code. They've spent countless hours navigating directories, grepping through files... If agents excel at filesystem operations for code, they'll excel at filesystem operations for anything."
Why This Format Works
The YAML format is both human-readable and machine-readable:
- Data teams can maintain it like any code
- The agent can grep, cat, and navigate it naturally
- Changes don't require redeploying the agent; it discovers updates at runtime
- The example_questions field helps the agent match user intent to the right entity
As Rauchg noted: "The agent is extremely effective thanks to our semantic layer defining the 'vocabulary' of how we reason about our business."
This is the insight that's easy to miss. The simplified tooling works because the semantic layer provides structure. Without clear definitions of what data exists and what it means, the agent would be lost.
What This Means for Data Teams
If you're a Head of Data or Analytics Engineer, here's why you should care: OpenAI's six-layer context system shows how larger organizations solve the same problem with more infrastructure.
1. Semantic Layers Aren't Optional Anymore
The common thread in every successful AI data agent is a well-documented semantic layer. Whether it's dbt semantic layer, Looker's LookML, or YAML files like Vercel's, the AI needs a source of truth for what data means.
If your data definitions live only in tribal knowledge or scattered documentation, AI agents will struggle. The investment in semantic infrastructure pays dividends when you want to layer AI on top.
Already have a semantic layer? You're ahead. If you're using:
- dbt semantic layer → Your MetricFlow YAML files are already in the right format
- Looker/LookML → Your explore and view definitions contain the same info
- Cube.js → Your schema files work similarly
The question becomes: can your AI agent access these definitions at runtime?
2. Don't Over-Engineer Your AI Tools
The instinct is to build specialized tools for every use case. Resist it. Every specialized tool you build is:
- More code to maintain
- More opportunities for bugs
- More decisions the agent has to make
- Less opportunity for the model to reason
Start with primitives. Add specialized tools only when you've proven they're necessary.
3. The Best Architectures Are Almost No Architecture
Vercel's conclusion is striking:
"Maybe the best architecture is almost no architecture at all. Just filesystems and bash."
This applies beyond text-to-SQL. Whenever you're building AI for data, ask: "Am I adding complexity that prevents the model from doing what it's already good at?"
4. Example Questions Are Underrated
Notice how Vercel's catalog includes example_questions for each entity. This isn't just documentation; it's a retrieval mechanism. The agent can grep for keywords from the user's question to find the right entity.
If you're building a semantic layer for AI, include example questions. They bridge the gap between how users ask and how data is structured.
The Broader Shift
d0 represents a shift in how we think about AI agents. The first generation of agent architectures focused on giving AI capabilities: more tools, more functions, more specialized logic.
The emerging approach focuses on giving AI access: access to information, access to execution environments, access to the same resources a human would use. Then trusting the model to figure out how to use them.
This doesn't mean tools are useless. You still need a way to actually run SQL. You still need sandbox environments for security. But the balance is shifting toward fewer, more general tools with richer context.
For data teams, this means:
- Invest in documentation. Clear naming, well-structured semantic layers, good descriptions. This is the context your AI will use.
- Trust the models. They're better at reasoning through multi-step problems than most specialized tools you could build.
- Simplify aggressively. If a tool exists only to make things "easier" for the model, you're probably making them harder. DoorDash takes the opposite approach, building sophisticated multi-stage validation for enterprise scale.
At Dot
We've been building AI agents for data analysis for several years now. We connect to warehouses, generate SQL, create visualizations, answer business questions.
Our experience aligns with what Vercel discovered: the power isn't in the number of tools you give an agent. It's in the quality of the context and the room you give it to reason.
When we've simplified our agent architecture (consolidated tools, invested in better prompting, trusted the model more) we've seen the same pattern. Better results. Faster responses. Fewer failures.
The details of our approach are different from d0's. We work across different data sources, handle visualization, operate in different channels. But the principle is the same: give capable models room to think.
If you're exploring AI for your data team, we'd love to show you what we've built.
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.