
How DoorDash Built an Internal AI Platform That Actually Works (2025)
What happens when a company processing 220 TB of data daily decides that dashboards aren't enough anymore?
DoorDash faced a problem familiar to every fast-growing data organization: knowledge was everywhere and nowhere at the same time. Experimentation results lived in one system, metrics in another, dashboards in Sigma, documentation in wikis, and critical context buried in Slack threads. Answering a business question meant a scavenger hunt across five different tools.
Their solution? An internal agentic AI platform that evolved from simple automation workflows to sophisticated multi-agent "swarms"—and the lessons from their journey offer a blueprint for any data team considering similar investments.
The Problem: Death by Context Switching
The scale of DoorDash's data challenge is staggering:
- 220 TB processed daily through their Flink streaming pipelines into their data lake
- 1.9 petabytes of data on disk across 300+ CockroachDB clusters
- 1.2 million queries per second at peak
- Thousands of experiments running in parallel monthly
- 12,000 Sigma users accessing analytics
- Billions of real-time events flowing through Kafka daily
With this scale came an inevitable problem: answering complex business questions required significant context-switching—searching wikis, asking in Slack, writing SQL, and filing Jira tickets. An analyst investigating a trend might spend more time finding data than analyzing it.
The Four-Stage Evolution: Workflows to Swarms
DoorDash didn't try to build an autonomous AI analyst on day one. Instead, they mapped out four distinct architectural stages, each building on the last:
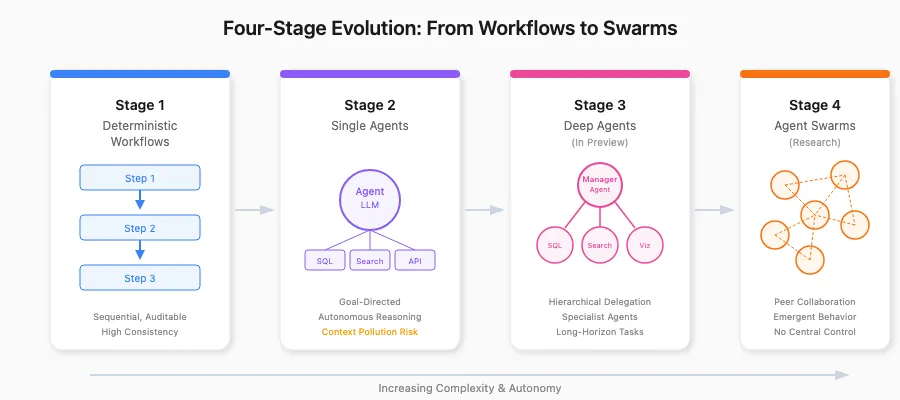
Stage 1: Deterministic Workflows
The foundation. Think of these as "factory assembly lines"—pre-defined, sequential steps optimized for repeatability. One workflow automates Finance and Strategy reporting by pulling data from Google Docs, Sheets, Snowflake, and Slack to generate business operations summaries and year-over-year analyses.
When to use: High-stakes tasks where consistency and auditability are paramount. Every step is logged, every output is traceable.
Stage 2: Single Agents
The first step toward autonomy. A single agent receives a goal, reasons about how to achieve it, and executes using available tools. Uber's QueryGPT exemplifies this stage, decomposing text-to-SQL into four focused agents. DoorDash's DataExplorer agent demonstrates this—it can interpret ambiguous requests like "Investigate the drop in conversions in the Midwest last week" by:
- Querying a metrics glossary to define "conversions"
- Calling an internal service to identify Midwest states
- Generating a precise SQL query against their warehouse
The limitation: Context pollution. As agents perform more steps, their context window fills with intermediate thoughts, degrading reasoning quality and limiting their ability to handle long-running tasks.
Stage 3: Deep Agents (In Preview)
To overcome single-agent limitations, DoorDash introduced "deep agents"—multiple agents organized hierarchically to manage complex, long-horizon tasks. The core principle is specialization and delegation: a manager agent coordinates specialist agents, each focused on a specific capability.
Use case: Market-level strategic planning that requires task decomposition across multiple data sources and analysis types.
Stage 4: Agent Swarms (Research Frontier)
Dynamic networks of peer agents collaborating asynchronously without centralized control. Unlike hierarchical deep agents, swarms operate through distributed intelligence where no single agent has the complete picture, but coherent solutions emerge through local interactions. DoorDash compares this to ant colonies rather than corporate org charts.
The challenge: Governance and explainability. Emergent behavior makes it difficult to trace exact decision paths.
The Technical Foundation: What Makes It Work
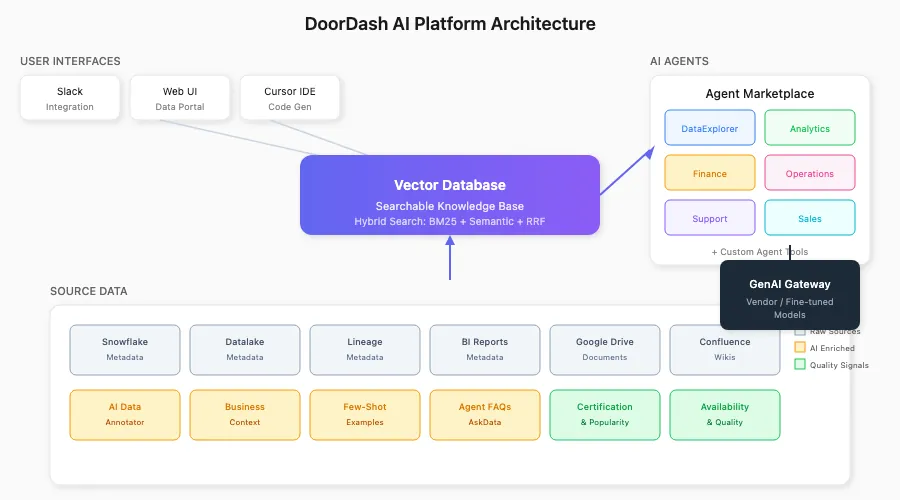
Hybrid Search with RRF Ranking
At the heart of the platform is a multistage search engine built on a vector database. DoorDash combines:
- BM25 keyword search for exact matching
- Dense semantic search for conceptual similarity
- Reciprocal Rank Fusion (RRF) re-ranking to merge results
This hybrid approach is critical because enterprise knowledge spans wikis, experimentation results, and thousands of dashboards—no single search paradigm captures everything.
Schema-Aware SQL Generation
Their "secret sauce" for accurate SQL: a custom DescribeTable tool that provides agents with compact, engine-agnostic column definitions enriched with pre-cached example values.
This pre-caching dramatically improves WHERE clause accuracy. When an agent needs to filter by country or product type, it has concrete examples—not just column names—to reference. The end-to-end flow:
Search → DescribeTable → SQL Generation → Multi-stage Validation → ResponseMulti-Stage Validation and Guardrails
Trust is built through transparency and reliability. DoorDash implemented a multi-layered guardrail system:
Platform-wide guardrails:
- EXPLAIN-based validation for all generated SQL to catch errors and anti-patterns before execution
- LLM behavior correction ensuring outputs adhere to company policy and formatting standards
Agent-specific guardrails:
- Custom rules like "this Jira agent cannot close tickets in project X"
- Full provenance logging—every answer traces back to source queries, documents, and agent interactions
LLM-as-Judge Evaluation Framework
For ongoing quality monitoring, DoorDash uses an LLM Judge that assesses performance across five dimensions:
- Retrieval correctness
- Response accuracy
- Grammar and language accuracy
- Coherence to context
- Relevance to the request
This automated oversight is what they consider non-negotiable for deploying AI into critical business functions.
The Results: Impact at Scale
Customer Support:
- 90% reduction in hallucinations through their two-tiered LLM Guardrail framework
- 99% reduction in severe compliance issues
- Escalation rates dropped from 78% to 43% in high-traffic message clusters
- 3 million chats per month powered by OpenAI APIs
Search Evaluation:
- 98% reduction in relevance judgment turnaround time compared to human evaluation
- 9x increase in evaluation capacity
Safety Moderation (SafeChat):
- 50% reduction in low- and medium-severity safety incidents
- Three-layered architecture where 90% of messages clear the first (low-cost) layer automatically
Finance Operations:
- 25,000 hours saved annually through Alteryx workflow automation
- Millions in ROI from end-to-end financial process automation
Open Standards: MCP and A2A
DoorDash isn't building in isolation. Their architecture embraces two emerging standards:
Model Context Protocol (MCP): Standardizes how agents access tools and data, ensuring secure, auditable interactions with internal knowledge bases. OpenAI's internal platform demonstrates MCP at scale, connecting 3,500 users to 600 petabytes of data. This is the bedrock of single-agent capabilities.
Agent-to-Agent Protocol (A2A): Developed by Google and donated to the Linux Foundation, A2A standardizes inter-agent communication. DoorDash sees this as key to unlocking deep agents and swarms at scale, enabling agent discovery, asynchronous state management, and lifecycle events.
Integration Strategy: Meet Users Where They Work
A critical insight: platform power means nothing without accessibility.
DoorDash's agents integrate directly with:
- Slack: Analysts can pull data directly into conversations without leaving the channel
- Cursor IDE: Engineers generate boilerplate code without context-switching
- Conversational Web UI: Central hub for discovering agents and reviewing history
This multi-surface strategy dramatically accelerates decision-making by eliminating the productivity drain of tool-switching.
The Hard-Won Lessons
1. You Can't Skip the Foundations
"Building a robust multi-agent system is a journey of increasing complexity and capability. You can't jump straight to sophisticated, multi-agent collaboration; you must first build a solid foundation."
Advanced multi-agent designs only amplify inconsistencies in underlying components. DoorDash spent significant time perfecting single-agent primitives—schema-aware SQL generation, multistage document retrieval—before attempting agent collaboration.
2. Build a Portfolio, Not a Silver Bullet
DoorDash doesn't try to replace one paradigm with another. Their approach:
- Deterministic workflows for critical reporting where auditability is paramount
- Single agents for ad-hoc data exploration and day-to-day questions
- Deep agents for complex analytical projects requiring task decomposition
- Swarms (research phase) for real-time logistics challenges
Different problems need different tools.
3. Guardrails Are Non-Negotiable
Every production AI system needs:
- Input validation before execution
- Output verification against company policies
- Full provenance tracking for auditability
- Human oversight loops for high-stakes decisions
4. Context Windows Are a Constraint, Not a Feature
The shift from single agents to deep agents was driven by a practical limitation: as agents perform more steps, their context fills with intermediate reasoning, degrading quality and increasing costs. Hierarchical delegation keeps each agent's context focused.
5. Shared Memory Enables True Collaboration
For deep agents and swarms, a persistent workspace—more than just a virtual file system—allows agents to create artifacts that others can access hours or days later. This enables collaboration on problems too large for any single agent's context window.
How This Compares to Other Approaches
vs. Databricks/Snowflake AI Assistants:
Platform vendors like Databricks (Agent Bricks) and Snowflake (Intelligence) offer point solutions for querying data in natural language. DoorDash's approach is more ambitious—a unified cognitive layer across all enterprise knowledge, not just the data warehouse.
vs. Generic RAG Systems:
Most RAG implementations retrieve documents and generate answers. DoorDash adds schema-aware SQL generation, pre-cached examples for filtering accuracy, multi-stage validation, and hierarchical agent delegation—a significantly more sophisticated stack. Airbnb's 13-model ensemble uses comparable validation patterns.
vs. Off-the-Shelf Agent Frameworks:
Frameworks like LangGraph provide building blocks, but DoorDash's implementation includes enterprise-specific capabilities: RRF-based hybrid search tuned for their data, custom lemmatization for table names, and guardrails integrated with their governance requirements. For a contrasting philosophy, Vercel's d0 removed 80% of tools and achieved 100% success with just file operations and bash.
Practical Takeaways for Data Teams
Start Building Now, But Start Small
- Map your knowledge topology: Where does critical information live? What context-switching patterns slow down your team?
- Invest in search first: A hybrid search engine combining keyword and semantic retrieval is foundational. You can't build smart agents on dumb search.
- Pre-cache schema examples: If you're building text-to-SQL, enriching column definitions with example values dramatically improves accuracy.
- Implement guardrails early: EXPLAIN-based SQL validation, output verification, and provenance logging should be built-in, not bolted on.
- Meet users in their tools: Slack integrations often deliver more value than standalone AI interfaces.
- Plan for the portfolio: Different use cases need different autonomy levels. Audit-critical workflows stay deterministic; exploratory analysis gets agent freedom.
Questions to Ask Before You Build
- Do you have the data infrastructure to support this? (DoorDash has 220 TB/day streaming, petabyte-scale storage, and mature data governance)
- What's your tolerance for non-deterministic outputs? Where do you need guarantees?
- How will you measure success? DoorDash uses LLM-as-judge frameworks and continuous human calibration.
- Can you staff the team? DoorDash's platform spans Foundations, Data, Analytics, and Product teams.
The Road Ahead
DoorDash's phased approach continues:
- Phase 1 (Launched): Platform foundation, marketplace, core single-agent primitives
- Phase 2 (Preview): Marketplace rollout, first deep-agent systems ("AI Network")
- Phase 3 (Exploration): A2A protocol integration, asynchronous swarm collaboration
The most interesting work—swarms of agents solving complex, real-time logistics challenges—is still on the research frontier. But the foundation is in place.
For data teams watching from the sidelines, the message is clear: the transition from dashboards to intelligent data platforms isn't theoretical anymore. Companies like DoorDash are building it today, learning from failures, and sharing the blueprint.
The question isn't whether AI will transform how organizations access data. It's whether you'll be ready when it does.
—
If this excites you, we'd love to hear from you. Get in touch.
Sources
- Beyond Single Agents: How DoorDash is building a collaborative AI ecosystem - DoorDash Engineering Blog
- How DoorDash is scaling AI to empower employees - OpenAI
- DoorDash: Building a Collaborative Multi-Agent AI Ecosystem - ZenML LLMOps Database
- DoorDash Data Tech Stack - Junaid Effendi
- How DoorDash manages 1.9PB and 1.2M QPS - CockroachDB
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.