
How Uber Built an AI Data Agent That Saves 140,000 Hours Every Month (2024)
What data leaders can learn from Uber's multi-agent approach to text-to-SQL
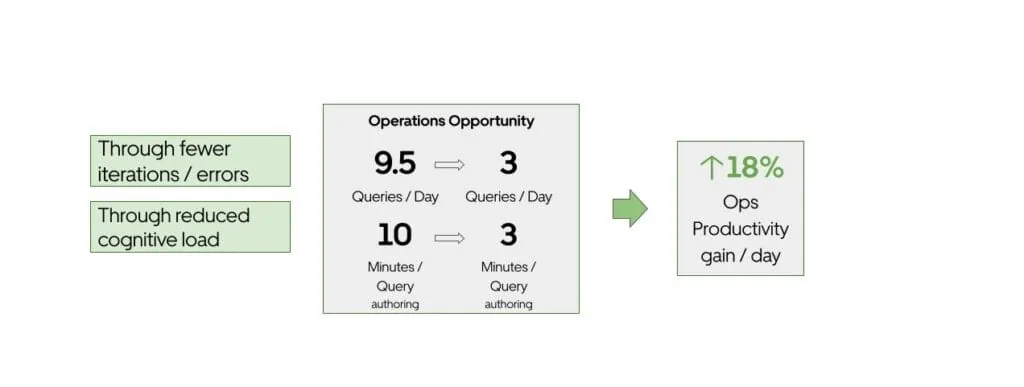
Seven minutes. That's how long the average Uber analyst spent writing a single SQL query before QueryGPT. Now it takes three minutes.
That might not sound revolutionary until you consider Uber's scale: 1.2 million interactive queries per month, with Operations alone responsible for 36% of them. At 10 minutes per query, the math was brutal. With QueryGPT, Uber now saves an estimated 140,000 hours monthly - equivalent to roughly $120 million in annual productivity gains.
But here's what makes Uber's story instructive for data leaders: they didn't get there by throwing GPT-4 at the problem and hoping for the best. They built a sophisticated multi-agent system through 20+ iterations, learned hard lessons about LLM limitations, and discovered that the key to AI success in enterprise data isn't raw model power - it's architecture.
The Problem: SQL Knowledge as a Bottleneck
Uber sits on petabytes of data spread across hundreds of thousands of tables. Engineers, data scientists, and operations professionals query this data daily to understand everything from driver utilization to restaurant delivery times.
But writing these queries requires two distinct types of expertise: SQL syntax mastery and deep knowledge of how Uber's internal data models represent business concepts. Finding people who have both is hard. Training them takes time. And even experts make mistakes when navigating complex schemas.
The result? Analysts spending more time constructing queries than analyzing results.
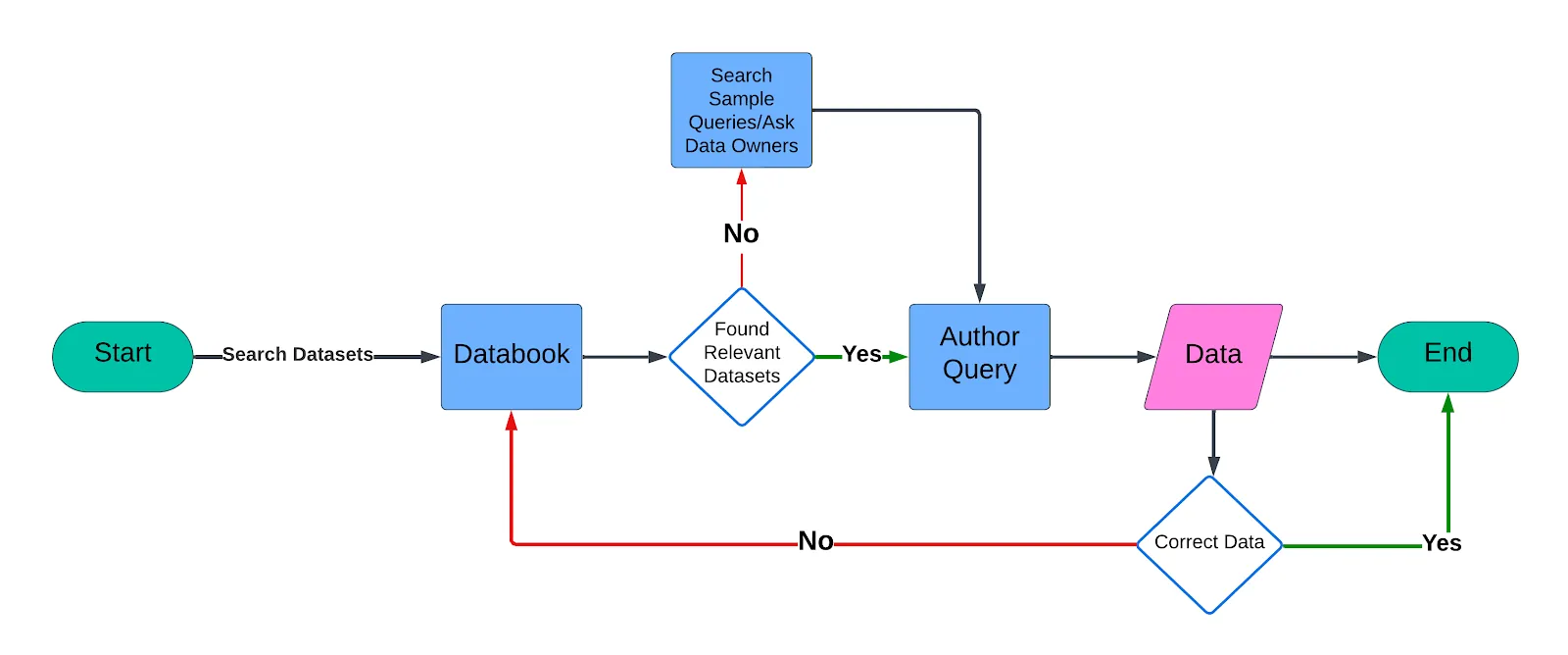
Version 1: The RAG Approach That Wasn't Enough
QueryGPT started as a hackathon project in May 2023. The initial approach was straightforward: vectorize user prompts, perform similarity searches against SQL samples and schemas, retrieve relevant context, and let GPT-4 generate the query.
This classic Retrieval-Augmented Generation (RAG) pattern worked... until it didn't.
As Uber onboarded more tables and SQL samples, accuracy declined. The system struggled with:
- Schema complexity: Some tables had 200+ columns, consuming massive token counts
- Token limits: Even with GPT-4 Turbo's 128K context window, some requests exceeded limits
- Domain ambiguity: User questions could map to multiple business areas
- Hallucinations: The model would generate queries referencing non-existent tables and columns
The team realized that a monolithic approach - feeding everything into one LLM call - wasn't going to scale.
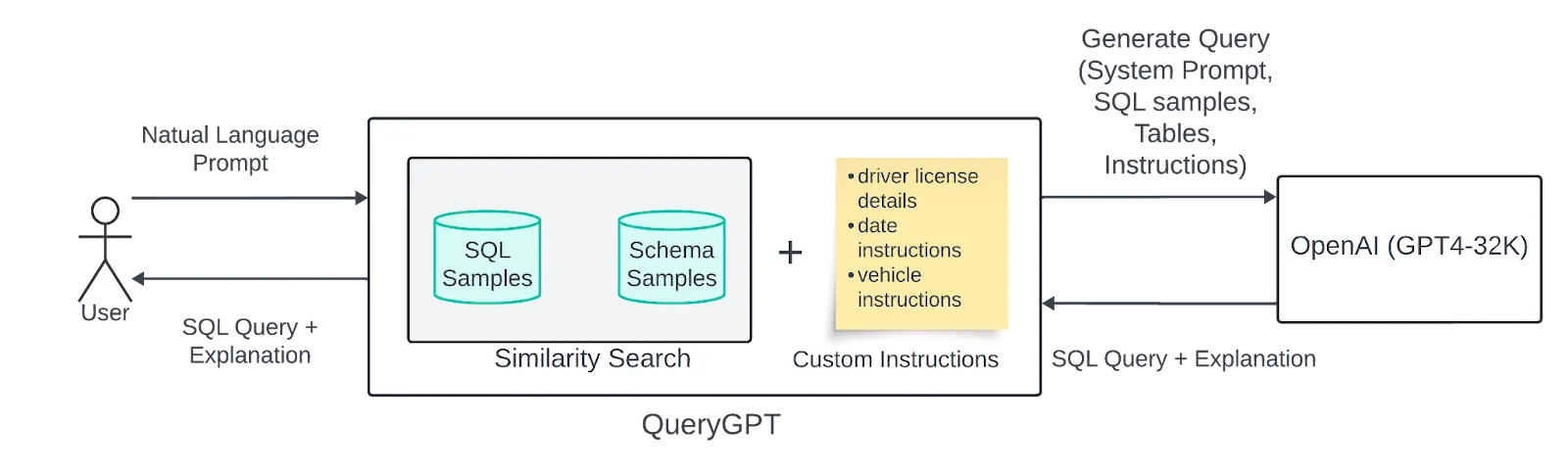
The Multi-Agent Architecture: Decomposition as Strategy
Instead of one generalized agent, Uber built four specialized ones. Each handles a focused task, passing refined signals to the next.
1. Intent Agent
Every user query first passes through the Intent Agent, which maps the question to one or more business domains. If someone asks about trip data, driver details, or vehicle attributes, the system routes to the Mobility workspace. Questions about ad performance go to the Ads workspace.
This classification happens through an LLM call - but it's a narrow, specialized classification task rather than open-ended generation. As the Uber team discovered, LLMs excel when given small, focused tasks.
2. Table Agent
Once the Intent Agent identifies relevant workspaces, the Table Agent proposes specific tables most likely to contain the required data. It performs similarity searches against Uber's metadata store, weighing historical query patterns and predefined relationships.
Critically, users can review and modify these selections. This human-in-the-loop approach isn't just about accuracy - it builds trust and catches domain-specific nuances that AI might miss.
3. Column Prune Agent
This agent solves the token limit problem. Even with the correct tables identified, schemas with hundreds of columns overwhelm LLM context windows. The Column Prune Agent uses an LLM call to filter out columns irrelevant to the user's question.
The benefits compound: fewer tokens means lower cost per call, faster processing, and simpler final queries. By removing noise before generation, the system produces more focused, maintainable SQL.
4. QueryGPT Agent
The final agent generates the actual SQL. Using few-shot prompting with domain-specific examples from the selected workspace, it produces executable queries with explanations.
The workspace concept is key here: rather than searching across all of Uber's SQL samples, the system works with curated collections tailored to specific business domains (Mobility, Ads, Core Services, etc.). This dramatically improves relevance while reducing the search space.
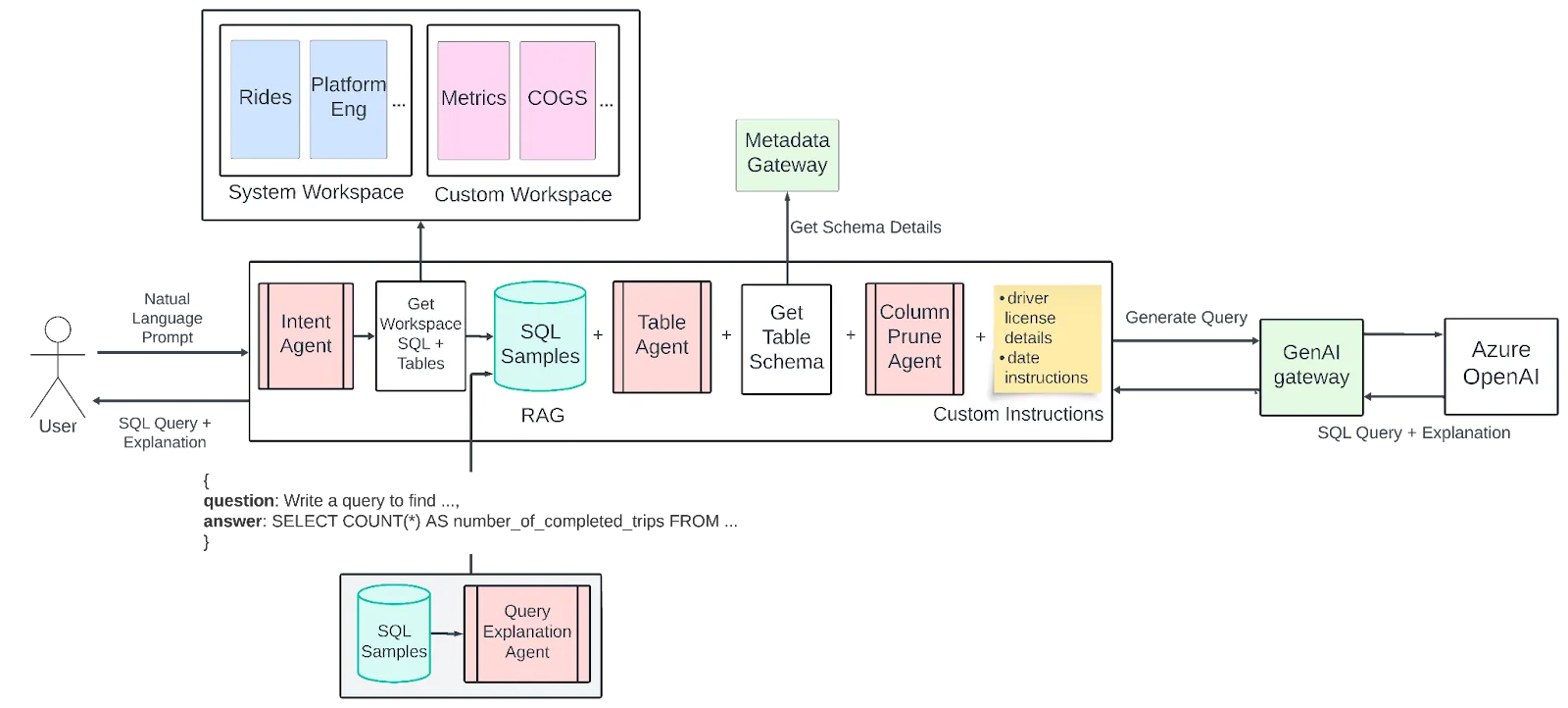
Why This Architecture Works
The Uber team's key insight: each agent succeeds because it's asked to do one thing well.
The Intent Agent classifies. The Table Agent retrieves. The Column Prune Agent filters. The QueryGPT Agent generates. Each handles a narrow task rather than a broad, ambiguous one.
This decomposition also makes the system debuggable and improvable. When accuracy drops, engineers can identify which stage is failing and address it specifically. A monolithic approach would make such diagnostics nearly impossible.
The Numbers: 78% Satisfaction and Growing
After a limited release to Operations and Support teams, QueryGPT averaged 300 daily active users. 78% reported that generated queries reduced the time they would have spent writing from scratch.
But perhaps more telling is how they measure success internally:
- Intent accuracy: Does the system correctly identify the business domain?
- Table overlap score: How well do selected tables match ground truth?
- Query execution success: Does the generated SQL run without errors?
- Result validation: Does the query return expected data (>0 records)?
- Qualitative similarity: How close is the output to expert-written SQL?
Uber runs two evaluation flows: "Vanilla" for end-to-end testing and "Decoupled" for component-level analysis. Given LLM non-determinism, they don't overreact to 5% run-to-run variations. Instead, they identify patterns over longer time periods.
Lessons Learned: What Data Teams Can Take Away
1. LLMs Are Better Classifiers Than Generalists
The counterintuitive finding: giving GPT-4 a narrow classification task outperforms asking it to "understand everything and generate SQL." Decompose complex problems into focused sub-tasks.
2. Workspaces > Universal Search
Domain-specific curation dramatically improves results. LinkedIn's knowledge graph approach validates this insight, achieving a 44-point accuracy improvement through metadata investment. By organizing SQL samples and tables into business-area workspaces, Uber reduced noise and improved relevance. This is essentially a form of semantic partitioning for RAG.
3. Token Management Is an Architectural Problem
Column pruning isn't an optimization - it's a necessity. Large enterprise schemas will exceed context limits. Build mechanisms to intelligently reduce what you send to the model.
4. Human-in-the-Loop Isn't a Crutch
Letting users review and modify table selections isn't a failure of the AI - it's a feature. Domain experts catch nuances, edge cases, and context that models miss. Design for human oversight, not full automation.
5. Hallucinations Are Still Real
Despite sophisticated architecture, Uber's system still generates queries with non-existent tables or columns. They've experimented with prompt refinements, introduced chat-style iteration, and are developing a Validation Agent. This problem isn't fully solved.
6. User Expectations Are High
Analysts expect near-perfect SQL. Targeting the right personas for initial rollout matters - users with some SQL knowledge can spot and fix issues, while purely non-technical users may be blocked by any imperfection.
The Broader Context: Why Multi-Agent Matters
Uber's QueryGPT represents a broader shift in enterprise AI: from monolithic models to orchestrated systems. DoorDash maps this evolution through four stages, from deterministic workflows to autonomous agent swarms.
The pattern shows up across industries. Complex enterprise problems - whether SQL generation, document processing, or customer support - increasingly use multiple specialized agents rather than single-model approaches. Airbnb's 13-model ensemble exemplifies this pattern in customer support automation.
This isn't just about performance. Multi-agent architectures offer:
- Debuggability: Isolate failures to specific components
- Modularity: Upgrade or replace individual agents without system rewrites
- Cost efficiency: Use smaller, cheaper models for narrow tasks
- Adaptability: Add new agents as requirements evolve
What's Next for QueryGPT
Uber's roadmap includes several promising directions:
- Validation Agent: Recursively attempting to fix hallucinations before presenting results
- RLHF loops: Reinforcement learning from human feedback for continuous improvement
- Query optimization: Automatic performance tuning and execution plan analysis
- Multi-modal support: Chart generation and data visualization alongside SQL
- Cross-domain analytics: Queries spanning multiple business areas
For Data Leaders Building Similar Tools
If you're considering building (or buying) an AI data agent, Uber's experience offers clear guidance:
1. Start with domain boundaries. Define workspaces before building. Curated SQL samples in specific business areas will outperform universal retrieval.
2. Design for token limits from day one. Large schemas are inevitable. Build column pruning or equivalent mechanisms early, not as an afterthought.
3. Plan for multi-agent orchestration. Single-model approaches hit walls. Decompose into focused agents that each handle one task well.
4. Measure component-level metrics. End-to-end accuracy alone won't tell you what's broken. Track intent classification, table selection, and generation quality separately.
5. Keep humans in the loop. Let users review and override AI decisions. This improves accuracy, builds trust, and catches edge cases.
6. Accept that hallucinations will happen. Build validation mechanisms, enable iterative refinement, and design UX that helps users catch and fix errors.
The productivity gains are real - 140,000 hours monthly at Uber's scale translates to transformative impact. But getting there requires architectural sophistication, not just access to the latest models.
The future of enterprise data isn't analysts versus AI. It's analysts amplified by AI - spending less time writing queries and more time understanding what the data means.
-
Sources: Uber Engineering Blog - QueryGPT
—
If this excites you, we'd love to hear from you. Get in touch.
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.