
Inside Stripe's AI Data Stack: Hubert, Toolshed, and the Data Discovery Problem
Emily Glassberg Sands, Stripe's Head of Data & AI, recently shared details about their internal AI infrastructure in a Latent Space podcast interview. The numbers are striking: 8,500 employees using AI tools daily, 900 people per week on their text-to-SQL assistant, 65-70% of engineers using AI coding assistants.
But the most interesting insight isn't about adoption. It's about what's actually hard: data discovery.
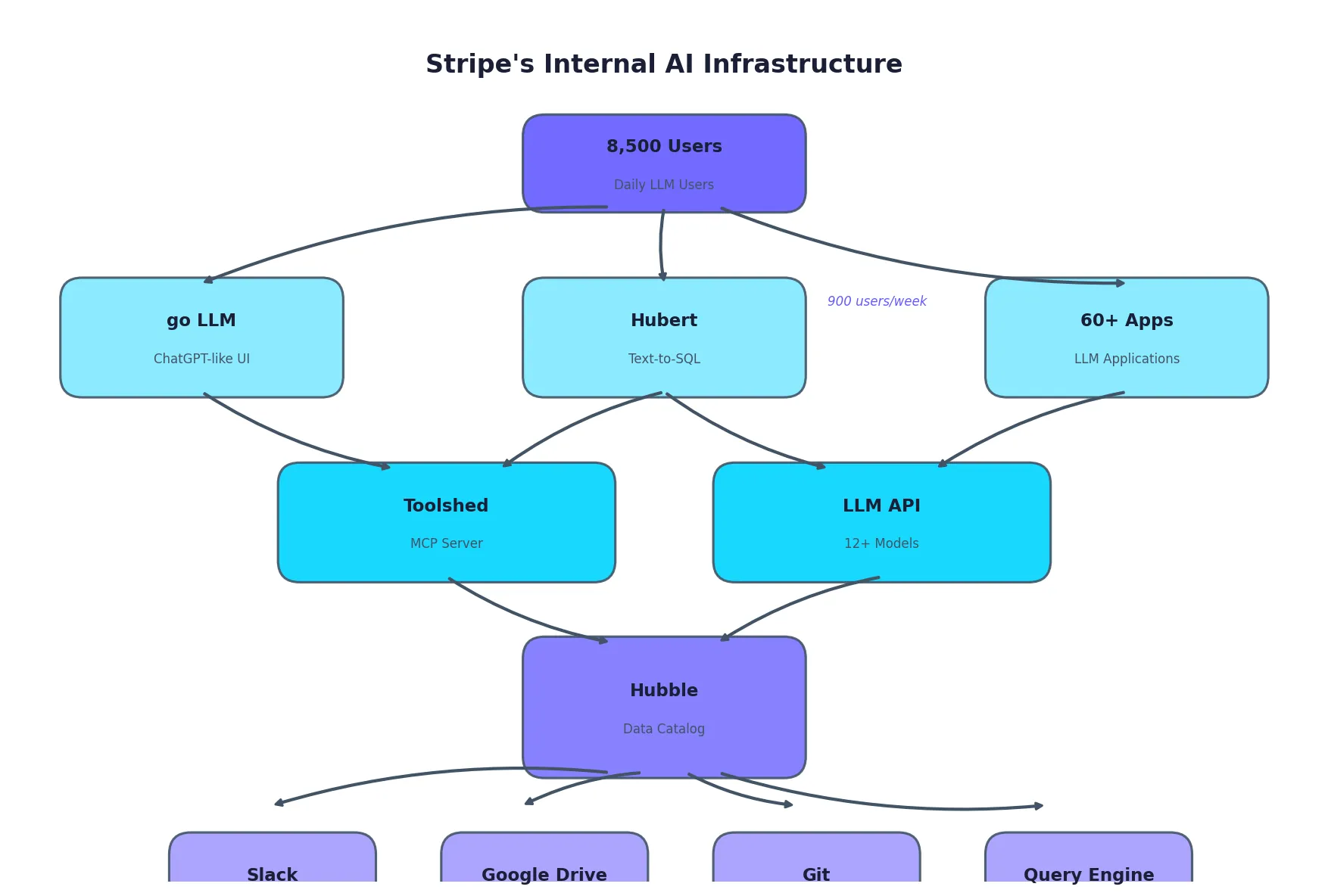
Hubert: Text-to-SQL at Scale
Stripe's internal text-to-SQL assistant is called Hubert. It sits on top of Hubble, their centralized data catalog, giving employees broad access to Stripe's data warehouse.
The usage is significant: approximately 900 Stripe employees use Hubert every week. That's nearly 10% of the company's workforce regularly querying data through natural language.
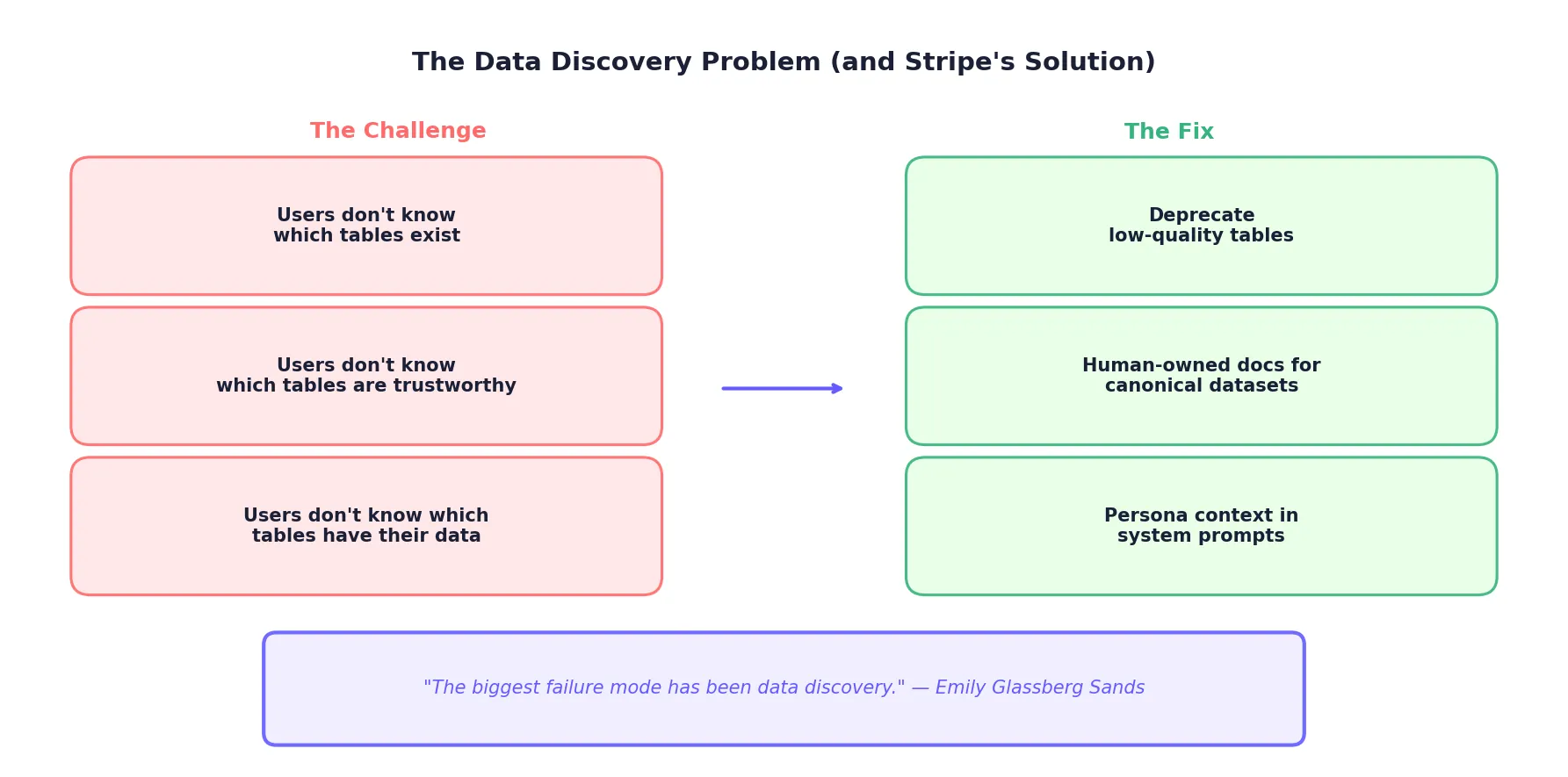
But here's the candid assessment: the biggest failure mode isn't SQL generation. It's table discovery.
"The biggest failure mode has been data discovery."
Users don't know which tables exist. They don't know which tables are trustworthy. They don't know which tables contain the data they actually need.
The Data Discovery Fix
Stripe's response wasn't to build a better model. It was to invest in upstream data governance:
1. Deprecating Low-Quality TablesTables that are stale, poorly maintained, or duplicative get deprecated. Fewer tables means less confusion for both humans and LLMs.
2. Human-Owned Documentation for Canonical DatasetsThe most important datasets get dedicated human documentation. Not auto-generated metadata, but carefully written descriptions of what each table contains and when to use it.
3. Persona Context as System PromptsWhen a user queries Hubert, the system knows "which org you're in" and uses that context to bias table selection toward appropriate sources. A finance analyst gets different table recommendations than an engineer.
This last point is subtle but powerful. Generic text-to-SQL treats all users the same. Stripe's approach recognizes that context determines relevance.
Toolshed: The MCP Server That Connects Everything
Beyond Hubert, Stripe built Toolshed: a central MCP (Model Context Protocol) server that provides "access to all the Stripe tools."
Toolshed connects:
- Slack
- Google Drive
- Git
- Hubble (data catalog)
- Query engines
The key insight is that Toolshed enables agents to both retrieve information and take actions. It's not just a read layer; it's an action layer that spans the entire organization.
This pattern, using MCP as the integration backbone, is emerging as a standard at companies with sophisticated AI infrastructure. ClickHouse and Airbnb are building similar systems.
The Canonical Data Problem
Stripe is re-architecting their data infrastructure with AI consumption in mind:
"Semantic events and real-time canonicals... re-architecting payments and usage billing pipelines so the same near-real-time feed powers Dashboard, Sigma, and data exports (e.g., BigQuery) with one source of truth that LLMs can consume."
The goal is a single canonical data layer that serves:
- The Stripe Dashboard (what customers see)
- Sigma (their SQL analytics product)
- Data exports to customer warehouses
- Internal AI tools like Hubert
When the data is canonical, AI tools work better. When it's fragmented across multiple sources of varying quality, every AI application inherits that confusion.
go LLM: Democratizing Model Access
Stripe's first internal AI use cases came from "bottom-up experimentation." They built "go LLM," a ChatGPT-like interface where employees can engage with multiple different models.
Behind go LLM is a backend service offered internally as an API that:
- Abstracts away LLM access
- Supports over a dozen models
- Provides security and reliability features
- Enables auto-model selection based on context size
- Logs all interactions for auditing
- Implements back-offs when hitting rate limits
This API powers over 60 LLM applications across Stripe. The pattern is clear: build the platform once, enable experimentation everywhere.
Sigma Assistant: Why Revenue Data Works
Stripe's external-facing Sigma Assistant (for customers analyzing their own revenue data) performs well because "revenue data is canonical."
When the underlying data structure is well-defined and reliable, text-to-SQL becomes dramatically easier. The lesson for internal tools: invest in data quality before investing in model sophistication.
The Numbers That Matter
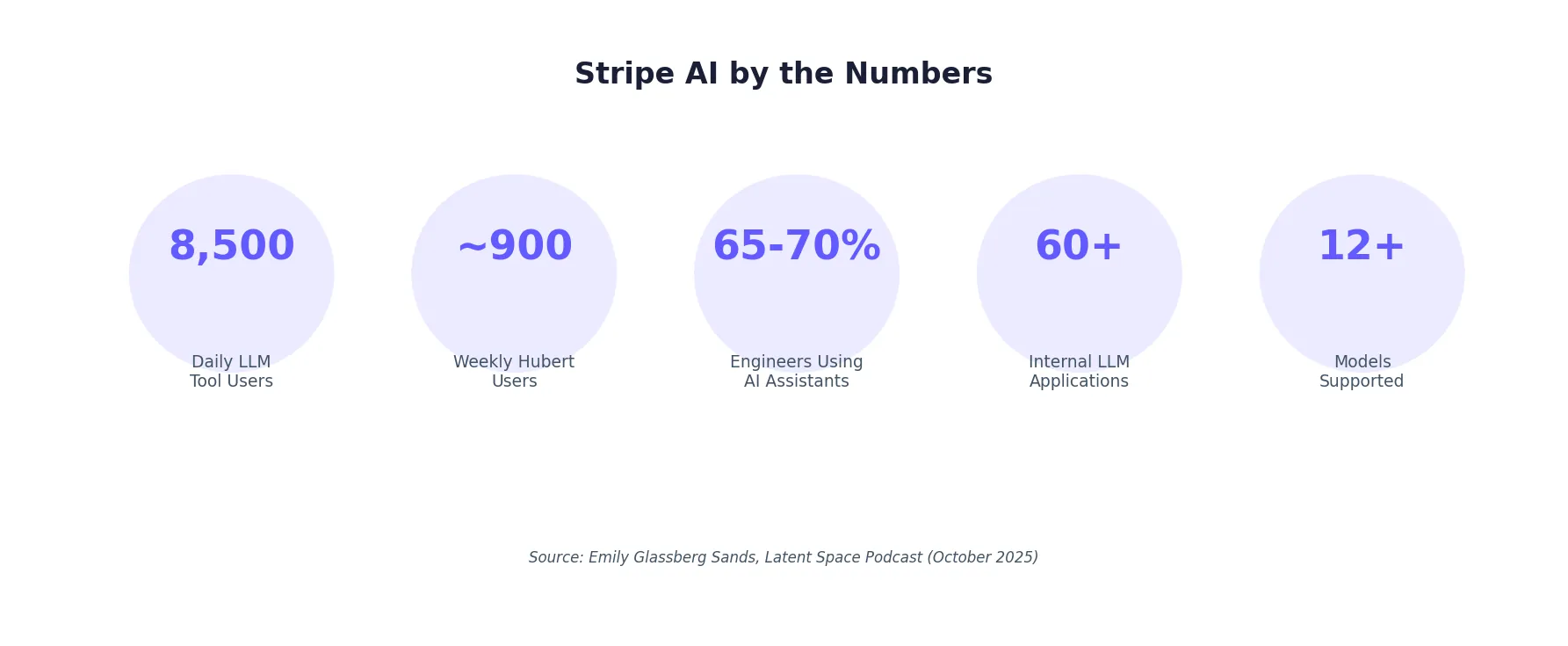
| Metric | Value |
|--------|-------|
| Daily LLM tool users | 8,500 |
| Weekly Hubert users | ~900 |
| Engineers using AI coding assistants | 65-70% |
| Internal LLM applications | 60+ |
| Models supported | 12+ |
These aren't pilot program numbers. This is production-scale adoption across a 10,000-person company.
Measuring Impact Beyond Code
Stripe has moved beyond simple metrics like "lines of code per PR":
"Impact is measured beyond lines of code/PR counts, focusing more on developer perceived productivity."
This matters because AI assistance changes how work gets done, not just how much code gets written. Developers might write fewer lines of code that are better quality. They might spend more time on architecture and less on boilerplate.
Measuring perceived productivity captures these shifts in a way that output metrics miss.
What Data Teams Should Steal
1. Data discovery is the bottleneck. Don't optimize SQL generation until you've solved table discovery. Deprecate bad tables. Document good ones. 2. Persona context improves relevance. Know who's asking and use that to filter results. A finance user and an engineering user need different tables. 3. Build the platform, enable experimentation. Stripe's internal LLM API powers 60+ applications. One abstraction layer, many use cases. 4. Canonical data makes everything easier. When the same data source powers dashboards, exports, and AI tools, consistency is built-in. 5. MCP is the integration pattern. Toolshed's ability to both retrieve and act across tools is the future of enterprise AI infrastructure.The Scale of the Opportunity
Stripe processes approximately $1.4 trillion in payments annually, representing roughly 1.3% of global GDP. At that scale, even small improvements in data access efficiency compound massively.
But the lessons apply at any scale. The hardest problem in enterprise AI isn't the model. It's the data. Stripe's approach, investing in data governance, documentation, and canonical data structures, is the foundation that makes AI applications actually work.
The Bottom Line
Stripe's AI infrastructure offers a masterclass in pragmatism:
- Hubert works because they fixed data discovery first, not because they found a better LLM.
- Toolshed works because MCP provides a standard integration layer, not because they built custom connectors for every tool.
- go LLM works because they abstracted model access, enabling 60+ applications without 60+ integrations.
The model is a commodity. Your data architecture is the competitive advantage.
Related reading:- Uber's Finch: The Financial Data Agent That Lives in Slack
- ClickHouse's AgentHouse: When a Database Company Bets on AI Agents
- Ramp Research: The Analyst Agent That Answers 1,800 Questions a Month
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.