
Ramp Research: The Analyst Agent That Answers 1,800 Questions a Month
They built an AI analyst in Slack. Now 300 employees ask it questions instead of waiting for the data team.

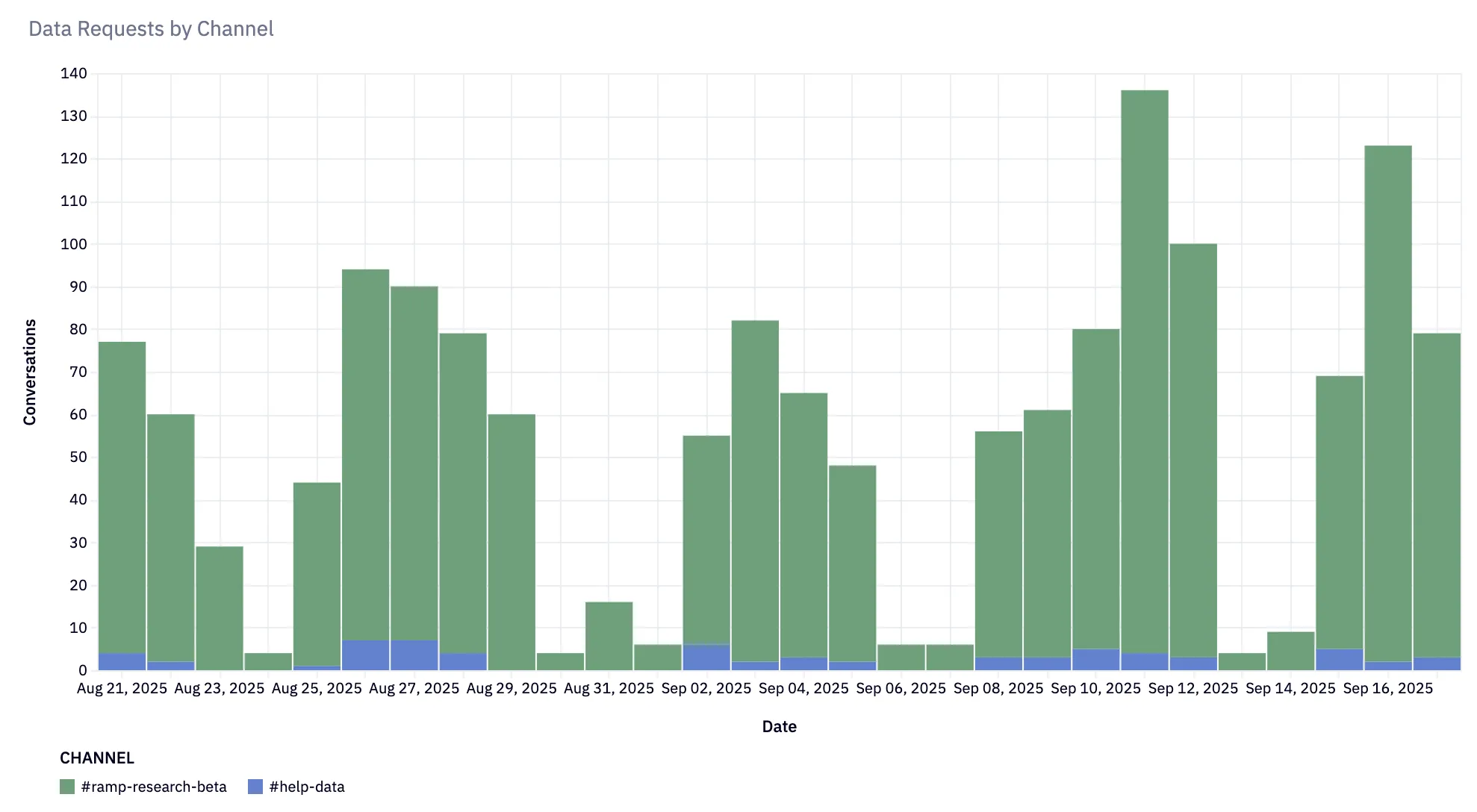
Ramp just published a detailed breakdown of Ramp Research, their internal AI analyst agent. The numbers are striking: 1,800+ questions answered since August, 300 different users, and a 10-20x increase in question volume compared to their legacy help channel.
But the most interesting part isn't the metrics. It's the philosophy behind how they built it.
The Problem They Solved
Every data team knows this pattern. Questions queue up. Analysts triage. Decisions wait.
"Data questions don't exactly crash the system, but they quietly slow every decision."
Ramp's data team wasn't drowning in requests. They had a help channel. It worked. But it created a bottleneck: the cost of asking a question was high enough that most questions never got asked.
Ramp Research changed the economics:
| Metric | #help-data (legacy) | #ramp-research-beta |
|--------|---------------------|---------------------|
| Questions (4 weeks) | 66 | 1,476 |
| Users | Limited | 300+ |
| Response time | Hours to days | Minutes |
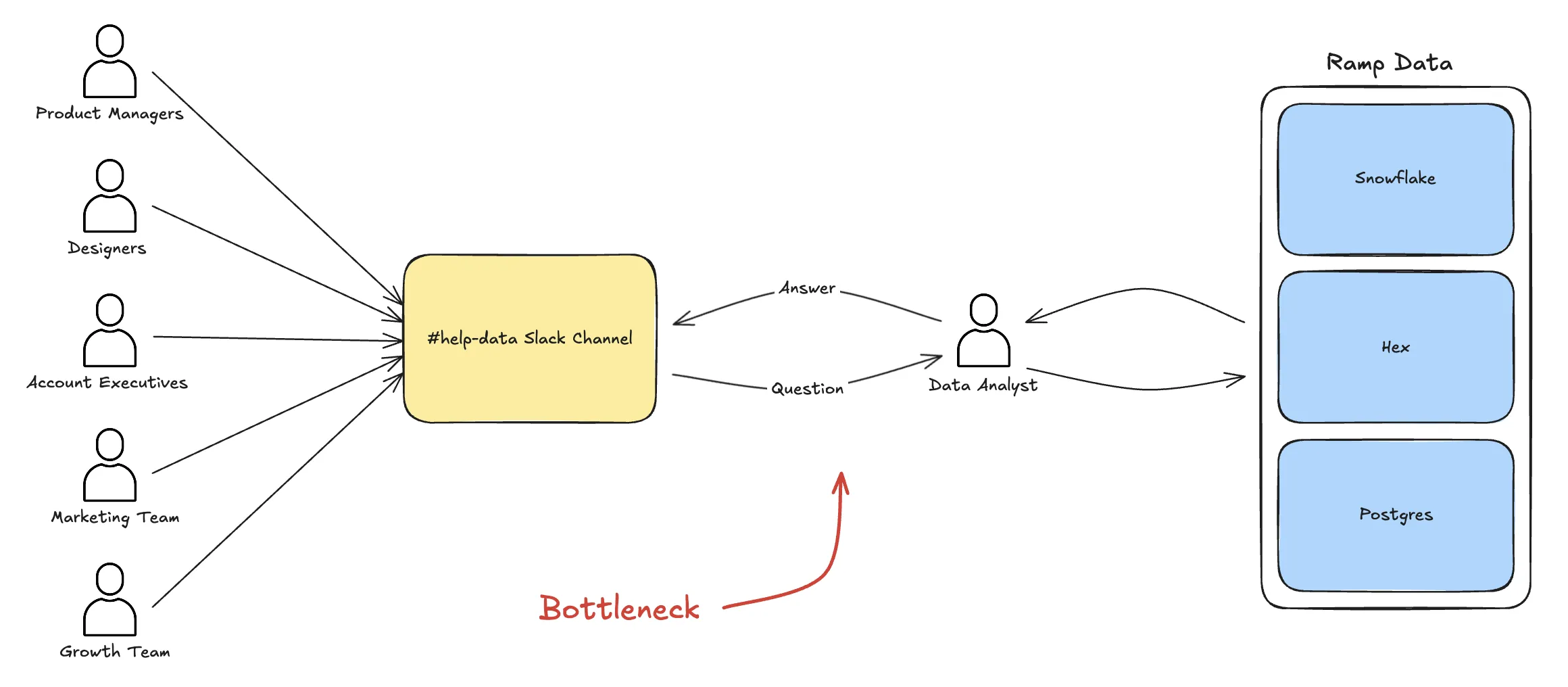
When asking a question costs nothing, everyone asks. The data team went from gatekeeper to enabler.
The Architecture
Ramp Research is built on their existing data stack: dbt, Looker, and Snowflake. No new infrastructure. No separate semantic layer.
The context layer aggregates metadata from all three sources:
- dbt: Table and column documentation, model relationships
- Looker: Explore definitions, measure calculations
- Snowflake: Schema information, sample values
Domain owners provide additional context through technical documentation organized in the dbt project itself. This is the key insight: context lives where the data lives.
The agent has a standard toolkit:
search_tables()for discoveryread_table_documentation()for schema detailsread_domain_document()for business contexttranslate_jargon()for terminologyrun_query()for direct SQL execution
When a user asks a question in Slack, the agent can inspect column values, branch through multiple hypotheses, and backtrack when needed, just like a human analyst would.
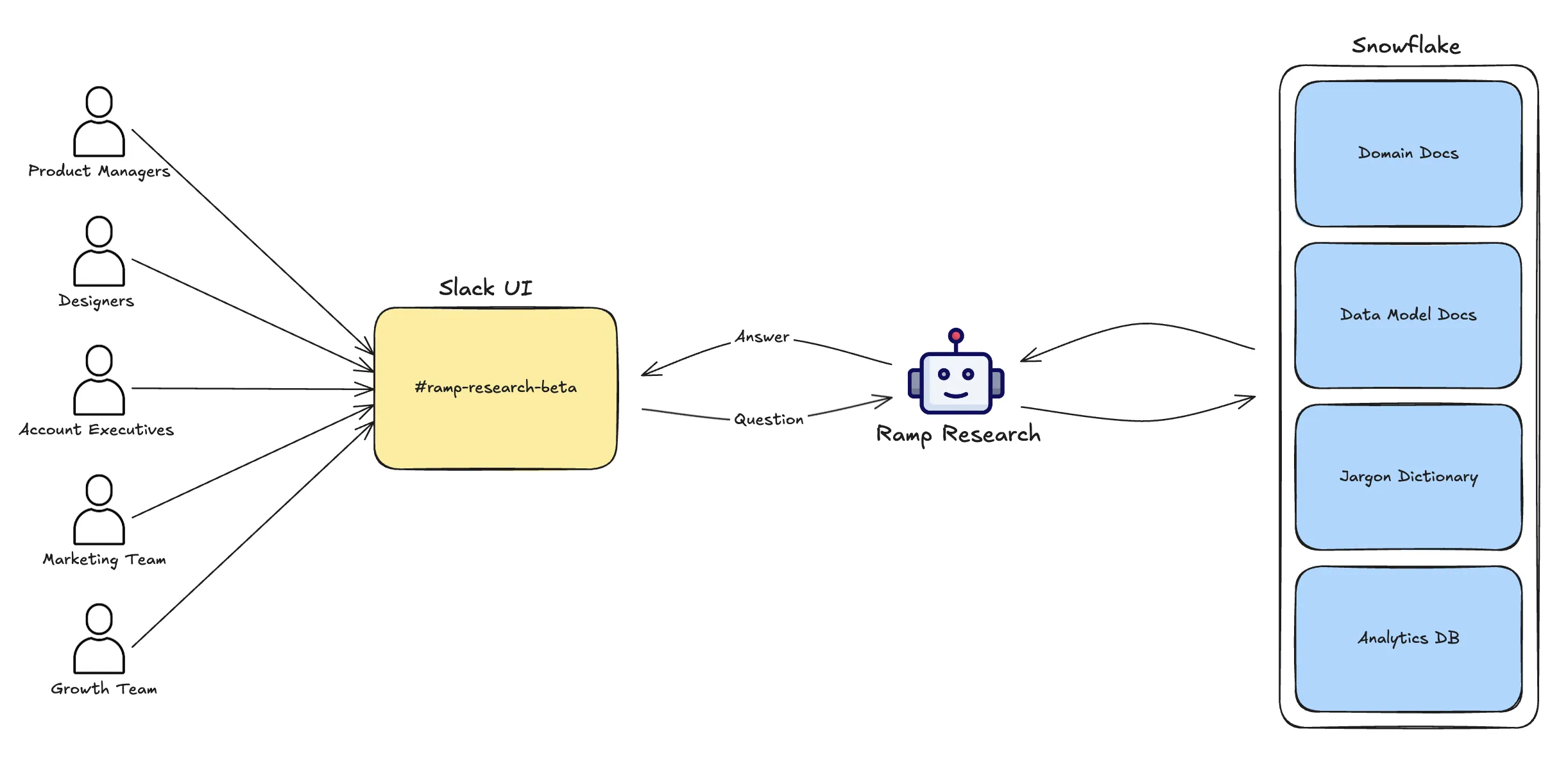
Slack-First Distribution
Ramp Research lives in Slack. Not a separate web app. Not a dashboard. Slack.
The #ramp-research-beta channel has 500+ members. Users get in-thread CSV previews for data validation. Conversations are multi-turn and stateful. The agent integrates into existing alert channels and project channels.
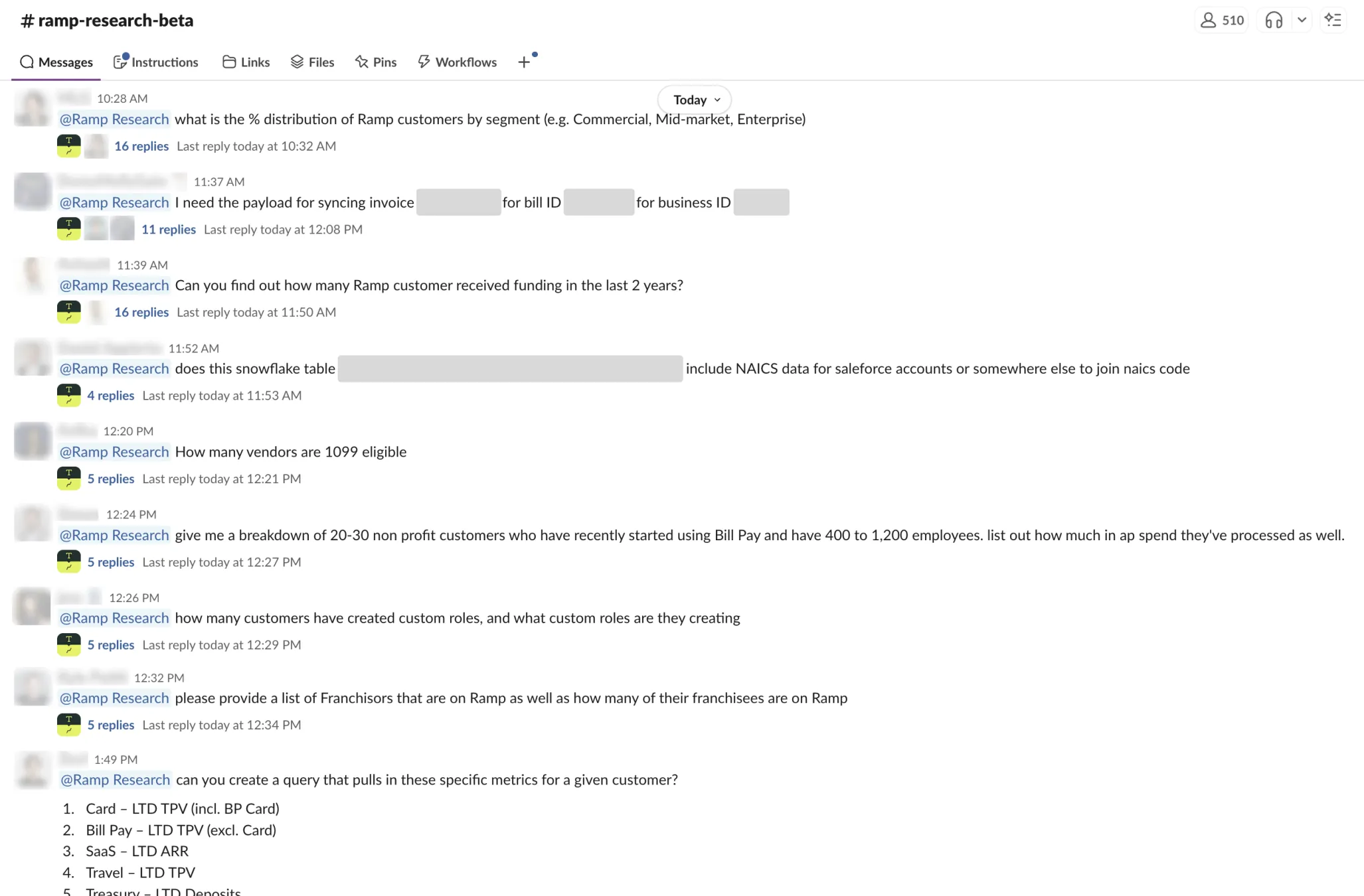
This matters more than the AI sophistication. As Ramp's team notes, they integrated the agent into workflows that already existed rather than asking users to adopt new behavior.
Jay Sobel's Take: dbt is the Foundation
Jay Sobel, Senior Analytics Engineer at Ramp and a key builder of Ramp Research, published a follow-up on his Substack explaining the technical philosophy.
His argument: most of the implementation belongs in your dbt project.
"dbt + Snowflake is my hammer. Internal agents look like a nail."
Sobel advocates storing everything in dbt:
- Jargon glossaries as seeds (CSVs)
- Domain documents as doc blocks in model YAML
- Tool implementations as dbt models querying Snowflake
- Context management tracked in version control
The advantage: context is code. It gets reviewed, tested, and versioned. When a metric definition changes, the agent's context changes with it.
The Anti-Semantic Layer Argument
In a separate post, Sobel makes a provocative claim: semantic layers don't make sense.
"Creating comprehensive semantic metadata for this complexity is like bringing a label printer to a jungle."
His alternative: good naming and written prose.
"Just. Write. Paragraphs."
Rather than building elaborate YAML-based semantic frameworks, Sobel argues for:
- Renaming tables and columns clearly
- Writing plain English documentation
- Using SQL as the interface (leveraging LLMs' training data)
The agent becomes a "Trojan Horse" that forces the organization to invest in proper data naming and documentation. Frame it as "AI Readiness" and suddenly everyone cares about metadata quality.
Ian Macomber's Philosophy
Ian Macomber, Ramp's Head of Analytics Engineering and Data Science, provides the organizational context.
His view on data teams: they shouldn't be service organizations.
"They're not data science support for the accounting pod. They are the accounting pod."
Ramp embeds data professionals directly into product teams. Each pod includes a product manager, tech lead, engineers, analytics engineer, and data scientist. Data isn't a support function; it's a core capability.
His contrarian take on measurement:
"Use a data science model or an A/B test as an absolute last resort. The phrase 'measure everything' is actually really lazy."
Simple SQL analysis achieves 80% of needed insights. A/B tests should only deploy when you genuinely cannot proceed without experimental evidence.
And on building vs. buying:
"Code isn't an asset, it's a liability."
Ramp prefers vendors for undifferentiated heavy lifting. The implication for AI agents: build what's core to your business context; buy the infrastructure.
What Makes This Work
Ramp Research succeeds because of several factors that are hard to replicate:
The agent lives where work happens. No behavior change required.
Context is versioned, reviewed, and deployed alongside the data models it describes.
Data professionals sit in product pods, so they understand the questions before they're asked.
Someone has to write those domain documents. At Ramp, domain owners own their context.
They built a Python testing framework in the dbt project for validating agent behavior.
The Gap for Most Teams
Ramp is an $8 billion fintech company with a world-class data team. They have the engineering capacity to build custom agents. Most companies don't.
The pattern is clear: Slack deployment, dbt-based context, multi-source metadata aggregation. But executing on that pattern requires:
- Engineers who can build agent frameworks
- Analytics engineers who can design context architectures
- Domain experts willing to write and maintain documentation
- Infrastructure to host and scale the agent
For teams without those resources, the question becomes: what's the buy vs. build tradeoff?
The Ramp Research approach validates that analyst agents work at enterprise scale. It also reveals the investment required to make them work. Slack integration isn't optional. Context management isn't optional. Documentation isn't optional.
The companies that can't build their own Ramp Research will need platforms that provide these capabilities out of the box: Slack and Teams deployment, git-synced context management, and connections to existing data infrastructure without requiring custom engineering.
The Bottom Line
Ramp Research proves that AI analyst agents deliver real value at scale. 1,800 questions answered. 300 users served. A 10-20x increase in data accessibility.
The lessons:
Slack integration isn't a nice-to-have. It's the difference between a tool people use and a tool people forget.
The quality of answers depends on the quality of documentation. No shortcuts.
For companies already using dbt, the model documentation infrastructure is halfway to agent context.
Ramp Research is an internal tool. It's not customer-facing. That's the right scope for learning what works.
The 10-20x increase in questions matters more than any benchmark score.
The future of data teams isn't replacing analysts with AI. It's giving everyone access to analyst-quality insights, through agents that live in Slack, understand business context, and answer questions in minutes instead of days.
Related reading:
- ClickHouse's AgentHouse: When a Database Company Bets on AI
- Uber's QueryGPT: Multi-Agent Architecture for Enterprise Scale
- LinkedIn's SQL Bot: 95% Satisfaction Despite 53% Accuracy
If this excites you, we'd love to hear from you. Get in touch.
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.