
WordleBench
My relationship with Wordle is long. I first got into programming during COVID, right as Wordle was taking off. One of my friends (whom I had a crush on) was really good at it. Like, really good. She used to send me screenshots of her solving it within minutes of it dropping at midnight. I, on the other hand, kinda sucked. But unlike most normal human beings who either accept defeat or try to get better, I decided to cheat. I decided to use my newfound programming skills to cheat at Wordle.
Now this was pre-AI and I didn’t have ChatGPT to write it for me (gosh, I sound old), so I painstakingly spent a good week (maybe more) writing a Python script that helped me solve Wordle. It was beautiful, it was simple: a list of all five-letter words sorted by popularity, gradually filtered out using a good old-fashioned for-loop. Simple but efficient.Now while it didn’t help me impress her, it did get me into programming, and look where we are now lol.
Now I work at Dot (AI data analytics) and we play with LLMs (a lot). Inspired by random X posts claiming AGI is right around the corner, I wanted to see how an LLM stacks up against my old program. And hence WordleBench was born
The Benchmark
It’s pretty straightforward tbh — I chose 15 words and asked LLMs to guess them Wordle-style. Something like:
User: Make your first guess
AI : SLATE
User: S - Yellow
L - Gray
A - Gray
T - Green
E - Yellow
AI : <next_guess>The words were mostly random ones that came to mind:
parts, shoes, entry, heads, spine, class, abide, zebra, chalk, youth, gypsy, flute, tryst, depth, nerdsI tried making it not too easy but also realistic as to one might expect in wordle.
and here are the results:
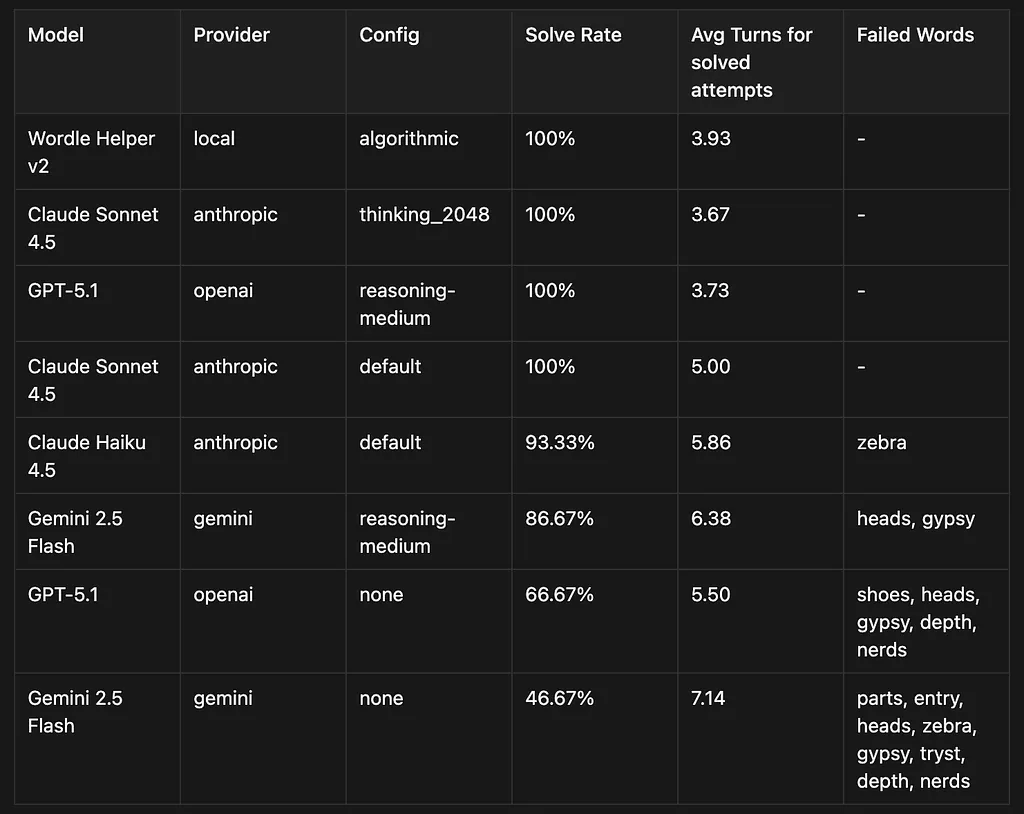
As you can see, having been trained on the entire internet means that LLMs definitely know their words.
Honestly I was a bit surprised by how good the models were ( with reasoning on ) and a bit dissapointed by how the benchmark seemed a bit saturated.
But I wasn’t ready to accept defeat just yet. Instead of giving textual feedback for each guess, I rendered an image that looks like Wordle and fed that back to the LLM. This means the LLM has to have good image understanding too. Results below:

Quick note: for this run I stopped the program at 5 guesses — this should have been 6, and I only realized it while writing this article. But since each LLM had the same constraints, I think it’s mostly ok.
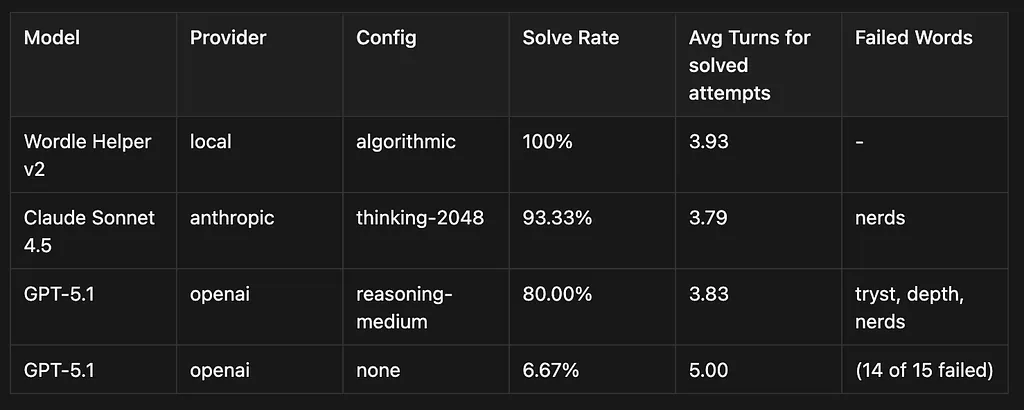
As you can see, the LLMs are still pretty damn good.
So unfortunately, my side quest to prove AGI isn’t around the corner will have to wait for another day. ¯\_(ツ)_/¯
Notes and thoughts while trying to create this benchmark
1. Gemini is bad in instruction following ( or at least worse than openai models ). Bunch of times it was producing weird artificats like the ones shown below
— this was with reasoning off — but it still gave this weird ‘THINK’ word (twice so I don’t think that was the guess — nothing else )

- Here we had reasoning on, but instead of keeping the reasoning internal, it spat it out in the response:
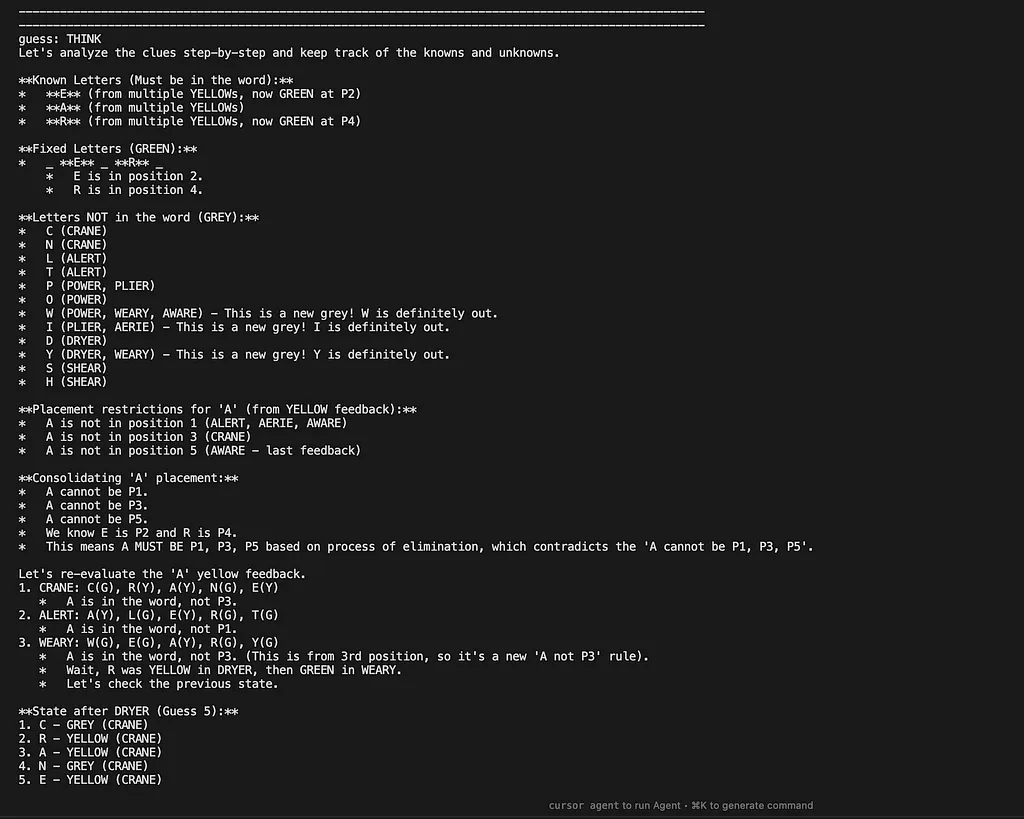
To be fair to Gemini, it was while reading through one of these reasoning traces (that shouldn’t have been there) that I found a critical bug in my grading function. My first implementation was naive and didn’t consider how many times a letter appeared in a word. For a guess like BITTE with FLUTE as the correct word, my program would output:
- B → Gray
- I → Gray
- T → Yellow
- T → Green
- E → Green
When the T in position 3 should have been gray. Gemini pointed this out in its reasoning, and I ended up correcting and rerunning the entire benchmark.
2. My love-hate relationship with Anthropic continues. On one hand, I’m a die-hard fan of their models — I’ve been daily driving Claude Code for months and prefer it over anything else. We use Sonnet for most of our agentic tasks. On the other hand, their API is SHITT.
— WHY DO U MAKE CACHING SO COMPLICATED ????
— Why is passing back thinking so much work ( tbf its not super ugly just very different than the other providers and when you are tryna benchmark this becomes a hassle )
Anthropic is the only provider for which I had to use the native SDK instead of LiteLLM because I wasn’t sure how LiteLLM handled the thinking blocks. (It probably would have worked fine, but I just wanted to rant a bit.)
References
WordleBench — https://github.com/zodwick/wordle_bench
Original Wordle Solver — https://github.com/zodwick/game-helper-cli-tools-for-wordle-and-sudoku
Related reading:
v2 of the Wordle Solver cause why not — https://github.com/zodwick/Wordle_helper--v2
Anand Ani
Anand is a co-founder of Dot. He builds the AI systems that turn natural language into trustworthy data answers. Before Dot, he spent years making complex data pipelines feel simple.