
Instacart's Intent Engine: Why Fine-Tuning Beats RAG

Instacart just published a deep dive into their Intent Engine, the LLM-powered system that handles search query understanding for millions of grocery shoppers. The most striking finding: a clear hierarchy of what actually works.
"Fine-tuning > Context-Engineering (RAG) > Prompting"
This isn't theoretical. They measured it across 95%+ of their query traffic.
The Problem: Long-Tail Queries
Search at Instacart is deceptively hard. "Milk" is easy. But what about "keto friendly snacks for road trip" or "something for my daughter's nut-free classroom party"?
Traditional ML models handled the head queries well enough. But the long tail, representing millions of unique searches, was where users struggled. Scroll depth was high. Complaints were frequent. Conversion suffered.
Their legacy system used multiple independent ML models for different tasks: query rewriting, category classification, attribute extraction. Each model needed its own training data, its own maintenance, its own failure modes.
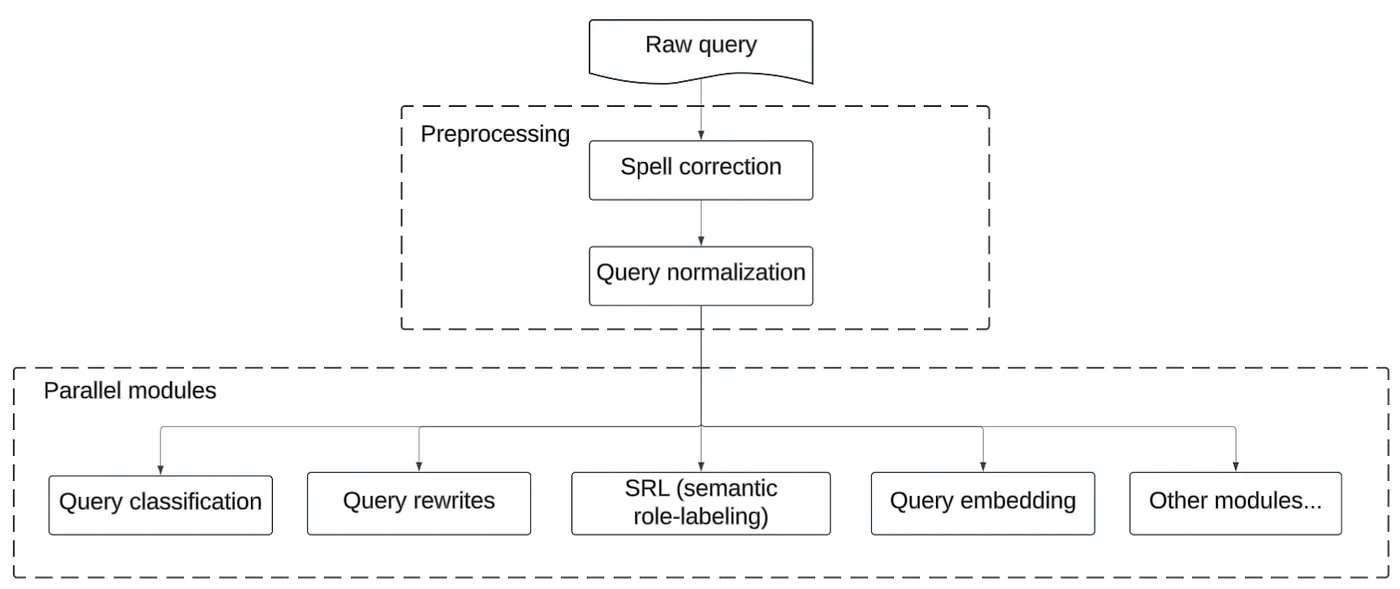
The goal: unify everything with LLMs while actually improving results.
The Hierarchy That Matters
Instacart's team tested three approaches at production scale:
Prompting worked for basic cases but couldn't handle Instacart-specific terminology, product relationships, or the nuances of grocery search. RAG (Context-Engineering) improved things significantly. They built pipelines that retrieved conversion history and catalog data, injecting business context directly into prompts. This grounded the model in reality. Fine-tuning won decisively. By training Llama-3-8B on proprietary data using LoRA (Low-Rank Adaptation), they embedded domain expertise directly into the model's weights.
The key insight: "A generic LLM is a commodity; your business context is what makes your application defensible."
The Hybrid Cache Strategy
Here's where production engineering matters. LLM inference is expensive. You can't run every query through a fine-tuned model in real-time, especially at Instacart's scale.
Their solution: a two-tier system.
Tier 1: Offline Teacher PipelineLarge frontier models with full RAG context process high-frequency "head" queries. Results are validated, cached, and served instantly. This handles 98% of traffic.
Tier 2: Real-Time Student ModelThe remaining 2% of queries (the true long-tail) hit a fine-tuned Llama-3-8B in real-time. It's smaller, faster, and trained via distillation from the larger teacher models.

This architecture means most users get sub-millisecond responses from cache, while novel queries still get intelligent handling.
The Numbers
The results speak for themselves:
| Metric | Before | After |
|--------|--------|-------|
| Query rewrite coverage | ~50% | 95%+ |
| Precision | Lower | 90%+ |
| Scroll depth (tail queries) | Baseline | -6% |
| User complaints (tail queries) | Baseline | -50% |
| Latency (real-time inference) | 700ms | <300ms |
That 50% reduction in complaints for tail queries is the number that matters most. These are the frustrated users who couldn't find what they needed.
Latency Engineering
Getting from 700ms to under 300ms required serious optimization:
- Adapter merging: LoRA adapters merged into base weights for 30% speedup
- H100 GPUs: Upgraded from A100s for faster inference
- Autoscaling: GPU capacity scales with traffic patterns to manage costs
- Quantization rejected: They tested it but prioritized recall over latency savings
The lesson: "The model is only half the battle. Production engineering determines whether potential becomes impact."
Post-Processing Guardrails
LLMs hallucinate. Instacart doesn't trust raw outputs.
Their three-step validation for category classification:
- Retrieval: Pull candidate categories from taxonomy
- LLM re-ranking: Score candidates with the fine-tuned model
- Semantic similarity guardrails: Filter outputs that don't align with known categories
This catches the "confidently wrong" responses that would otherwise degrade search quality.
Why This Matters for Data Teams
The Intent Engine validates patterns we've seen across enterprise AI projects:
1. Fine-tuning still wins for domain expertise. RAG is powerful, but when you have proprietary data and specific terminology, nothing beats encoding that knowledge in model weights. LinkedIn found similar results with their SQL Bot. 2. Hybrid architectures handle scale. The 98% cache / 2% real-time split is elegant. Most traffic is cheap; only novel queries pay the inference cost. This is how Uber's QueryGPT handles enterprise scale too. 3. Latency is a feature. 700ms felt slow. 300ms feels instant. The engineering work to bridge that gap determined whether users actually adopted the system. 4. Guardrails are mandatory. Post-processing validation isn't optional when LLM outputs affect user experience. Trust but verify.The Bottom Line
Instacart's Intent Engine joins a growing list of production LLM systems that prove the same point: generic models are table stakes. Your competitive advantage comes from business context, whether that's fine-tuning data, RAG pipelines, or domain-specific guardrails.
The hierarchy is clear: Fine-tuning > RAG > Prompting.
But here's the nuance they discovered: you often need all three. Fine-tuning for the core model. RAG for real-time context. Prompting for the interface layer. The question is where to invest most heavily for your specific use case.
For Instacart, with millions of products and infinite query variations, fine-tuning was worth the investment. For simpler domains, RAG might be enough.
The only wrong answer is assuming a generic LLM will understand your business out of the box.
Related reading:- Uber's QueryGPT: Multi-Agent Architecture for Enterprise Scale
- LinkedIn's SQL Bot: 95% Satisfaction Despite 53% Accuracy
- Pinterest's Text-to-SQL: Solving Table Discovery First
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.