
Gpt 5.2 is good but ...
Gpt 5.2 is good but …
Gpt 5.2 is the latest from OAI and it shows. In our internal benchmarks at Dot it achieved SOTA, but we probably won’t use it.
A bit about the benchmark :
At dot we really care about how good an LLM can write a sql query. But it is equally important that the LLM doesn’t write a query assuming a bunch of stuff it doesn’t know. Hence this benchmark rewards LLMs for asking the right clarifying questions ( when data is not sufficient ).
We have tried mimicking real world usage and have been using this internally for quite some while even though this is our fist time releasing any data.
Inspired from chess this benchmark measures how good an LLM is compared to another. The baseline we use right now is shown below
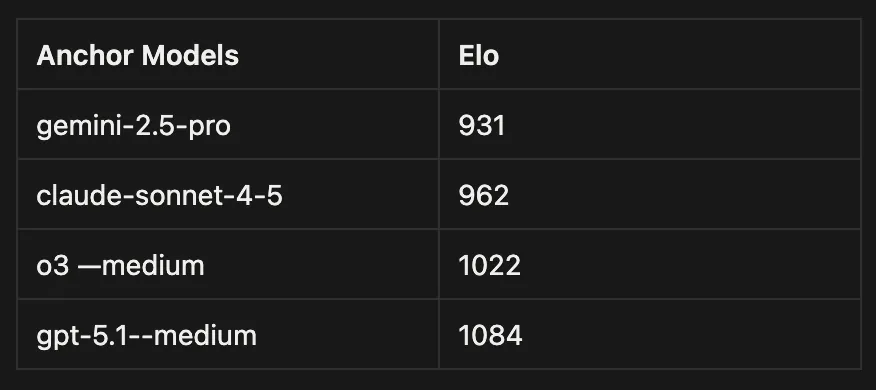
These Elos were decided by a sort of Round Robin match-up where we pit these models against each other. Few things to note here:
- Openai models were run with reasoning_effort set to medium.
- Gemini 2.5 pro and Claude ran with reasoning_tokens set to 4096.
- Claude 3–7 sonnet was used as the judging model.
The idea is to run all new models against these anchor models. and so we ran gpt-5.2 with medium reasoning and here are the results
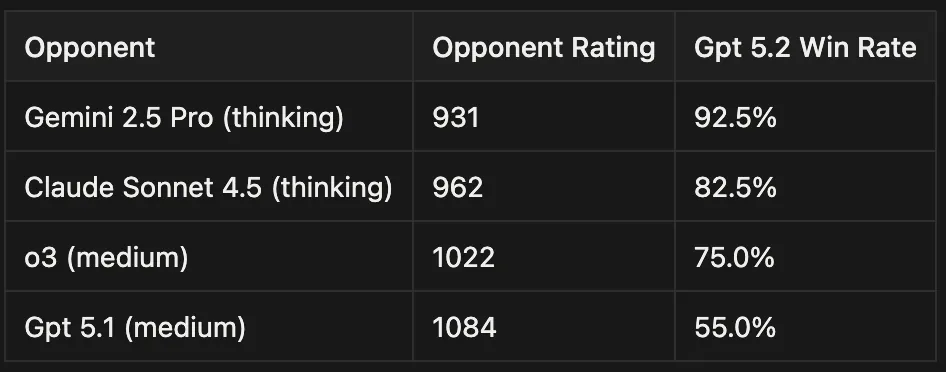
Overall: 57 wins, 15 losses, 8 ties across 80 matches (71.25% win rate)
This puts Gpt 5.2 with an impressive Elo of 1207
Here are some things we noted about this new model
- It consistently asked more ‘good’ clarifying questions ( short, to-the point, relevant ). Although there were scenerious where it went too far and tried overclarifying.
- When writing SQL, it tried handling multiple edge cases more
- Patterns the judges rewarded:
NULLIF(denominator, 0) -- division by zero protection
COALESCE(field, 'Unknown') -- NULL handling
LOOKUP('field', 'value') -- flexible matching vs exact stringsIf its so good why are we hesitant on switching ?- SPEED or the lack there of.
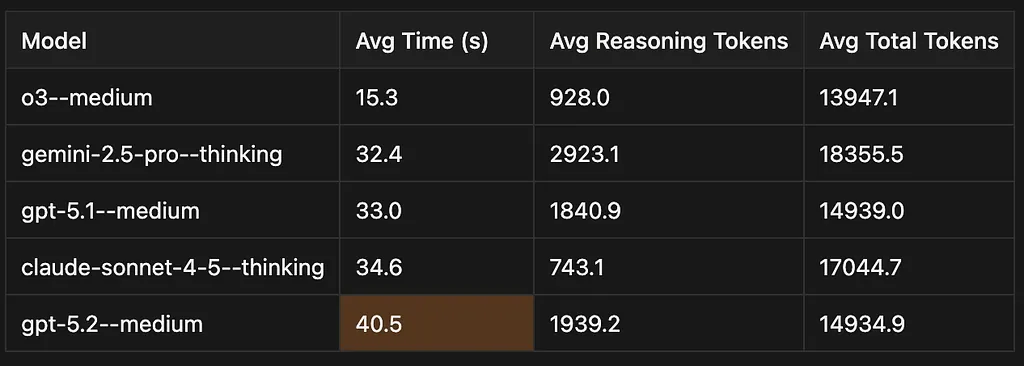
As you can see gpt 5.2 is the slowest on our benchmark taking 40 seconds on avergae !! that is almost 25% slower than gpt 5.1 !!
For a good user experience we have found that speed is as important as intelligence.
One notable thing here is how ridiculously fast o3 has become. Maybe this is due to the lowered demand ?
While we are here, one more thing I kind of hate about OpenAI right now is just how many models they have ! Even as someone who works with models all day it still confuses me. Gpt 5.2, gpt 5 nano, gpt 5 mini, gpt 5, gpt 5 .2 pro, gpt 5.1 codex, gpt 5.1 codex mini, gpt 5.1 codex max — like huh ?? This list is not even complete ! It does not even consider all the permutations with the reasoning effort . If you go to https://platform.openai.com/docs/models/ it is INASANEE !! I know that OAI has become synonymous with how bad their naming is but guys pleasee !! at least` make the names somewhat different so that I don’t have to go visit your model page 50 times a week.
Related reading:
We hope to run this benchmark and release the numbers on all new models that come out. Any feedback is much appreciated.
Anand Ani
Anand is a co-founder of Dot. He builds the AI systems that turn natural language into trustworthy data answers. Before Dot, he spent years making complex data pipelines feel simple.