
What Netflix's LORE Teaches Us About Building AI Data Assistants (2024)
Dashboards with less than 5 monthly active users. Metrics defined differently across teams. Business context locked in custom code. Sound familiar? Netflix faced the same analytics entropy that plagues most data organizations---and their solution offers a masterclass in building AI data tools that work.
In December 2024, Netflix's Analytics Engineering team unveiled LORE, an LLM-powered chatbot that lets anyone in the company have a conversation with their data. But what makes LORE worth studying isn't the LLM---it's everything around it.
The Problem: Analytics Products That Nobody Uses
Netflix's data team made a candid admission that should resonate with every data leader: despite tremendous investment in analytics products, they noticed troubling patterns:
The result? Business metrics and their context were "locked in custom code for each of the dashboard products." Sound familiar? This is the analytics sprawl that happens when good intentions meet organizational complexity.
Netflix's insight: the problem isn't too few dashboards---it's that dashboards create silos, and silos kill data trust.
LORE: Conversation Over Configuration
LORE (we assume it stands for something clever, but Netflix hasn't said) takes a fundamentally different approach. Instead of building another dashboard, they built a conversational interface that sits on top of their existing data infrastructure.
The core thesis: LLMs tie the versatility of natural language with the power of data query to enable business users to query data that would otherwise require sophisticated knowledge of underlying data models.
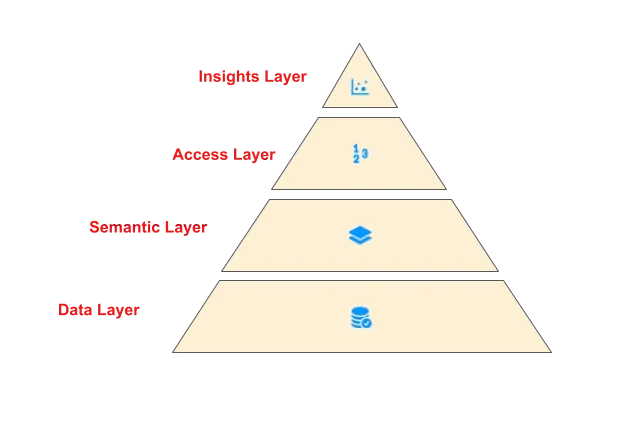
Netflix's Analytics Enablement pyramid - LORE sits at the Insights Layer
What Makes LORE Different
1. Explainability as a First-Class Feature
Netflix made a strategic bet that separates LORE from most AI data tools: they prioritized explainability over raw capability. As they put it, "To gain end users' trust, Netflix focused on the model's explainability."
LORE doesn't just return an answer---it provides:
This is the opposite of the "magic black box" approach. Netflix understood that in enterprise analytics, a trustworthy 80% answer beats an untrusted 95% answer every time.
2. The Fine-Tuning Flywheel
Here's where LORE gets clever. Netflix created a simple feedback mechanism---thumbs up/thumbs down---but connected it to a "fully integrated fine-tuning loop."
The result: LORE instantly learns from user feedback. This isn't just collecting data for quarterly model updates. Users actively teach the system new domains and questions, which allowed Netflix to bootstrap LORE across several domains rapidly.
Think about the organizational implications: the people who know the business best---the business users themselves---become the teachers. The data team doesn't have to anticipate every question; they just need to build the learning infrastructure.
3. Context-Rich Metric Understanding
LORE surfaces "internal business metrics that were previously locked in custom code for each of the dashboard products." This suggests integration with Netflix's DataJunction (DJ)---their open-source semantic layer that acts as a central store for metric definitions.
This is critical architecture. LORE isn't generating SQL against raw tables---it's working with governed metric definitions that have been vetted and standardized. The LLM provides the interface; the semantic layer provides the truth.
Graph Search: A Technical Deep-Dive into Netflix's RAG Approach
While LORE handles analytics queries, Netflix published detailed technical documentation about their Graph Search system, which converts natural language into their Filter DSL. The approaches share DNA, and the Graph Search work illuminates how Netflix thinks about LLM-powered data access.
The Three Levels of Correctness
Netflix frames the text-to-query challenge with unusual precision. They need generated queries to be:
The first two are tractable. The third is where it gets hard.
Handling Ambiguity: The "Dark" Problem
Netflix gives a revealing example: when a user searches for "Dark," do they mean:
This ambiguity "stems from the compression of natural language"---users naturally omit context that seems obvious to them. Netflix's data shows the median query length in their logs is just 1 token. On TVs, the median is just 3 characters.
Their solution combines multiple strategies:
RAG for Context Selection: They create embeddings for index fields and their metadata (name, description, type), then perform vector search at query time to identify relevant fields. This keeps context focused---important because "some indices have hundreds of fields, but most user questions typically refer only to a handful of them."
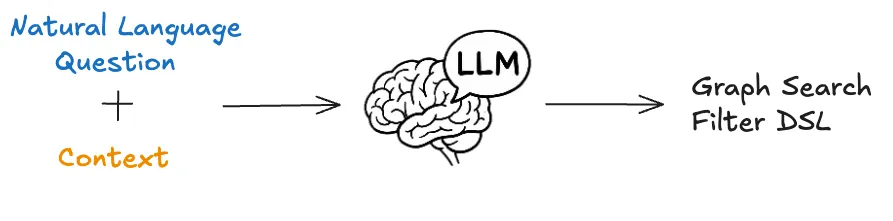
Netflix's RAG approach for context-aware query generation
Controlled Vocabulary Matching: When field values are constrained (like genres or moods), they embed those vocabularies separately and match against them. This prevents hallucinated values and helps disambiguate intent.
Self-Correction Loops: When hallucinations are detected, Netflix can either return an error asking the user to refine their query, or feed the error back to the LLM for self-correction. They note this "increases filter generation time, so should be used cautiously with a limited number of retries."
The Architecture Principle
The key insight from Graph Search: Netflix aims to "augment and not replace existing applications with retrieval augmented generation." They're not asking the LLM to do everything---they're using it as a translation layer between human intent and their existing, proven infrastructure.
How LORE Compares to Industry Approaches
Netflix isn't alone in building enterprise AI data tools. How does their approach stack up?
Uber QueryGPT
Uber's QueryGPT reports a 70% reduction in query time (from 10 minutes to 3 minutes per query) and 140,000 hours saved annually. Read more about Uber's multi-agent QueryGPT architecture. Their approach uses:
QueryGPT emphasizes productivity metrics. Netflix emphasizes trust and explainability. Different organizational priorities, different design choices.
LinkedIn SQL Bot
LinkedIn built SQL Bot into their DARWIN data science platform, converting natural language to SQL with strict access controls. Their focus: enabling non-technical employees to independently access insights while respecting data governance. LinkedIn's full SQL Bot case study explores their knowledge graph approach in depth.
Databricks Assistant
Databricks leverages Unity Catalog metadata to understand tables, columns, and popular data assets. Their differentiator: deep integration with the data platform itself, providing context that standalone tools lack.
What Netflix Does Differently
Netflix's distinctive contribution is the explainability-first design combined with the user-driven fine-tuning loop. Most enterprise tools optimize for accuracy or speed. Netflix optimized for trust---recognizing that adoption depends on users believing the answers, not just receiving them. For contrasting approaches, see how Vercel's d0 achieved 100% success rate by simplifying to just file operations and bash.
Actionable Takeaways for Data Teams
If you're building AI data tools, here's what Netflix's approach suggests:
1. Don't Start with the LLM---Start with the Semantic Layer
Netflix has DataJunction. Uber has Workspaces. Databricks has Unity Catalog. The pattern is clear: LLMs work better when they query governed abstractions, not raw tables.
If your metrics are scattered across databases, documentation sites, and code repositories (as Netflix admitted theirs were), fix that first. A mediocre LLM with great metadata will outperform a great LLM with poor metadata.
2. Make Explainability Non-Negotiable
Netflix's confidence scores and human-readable reasoning aren't nice-to-haves---they're core features. Users need to verify answers against their domain knowledge. If they can't, they won't trust the system. If they don't trust it, they won't use it.
Benchmark research shows LLMs without semantic context achieve below 20% accuracy on enterprise data queries. Even with context, accuracy varies. Users must be able to sanity-check results.
3. Build the Learning Loop from Day One
Netflix's thumbs up/thumbs down feedback connected to fine-tuning isn't just UX polish---it's the mechanism that lets them scale across domains without the data team becoming a bottleneck.
Consider: who knows best whether a query about "customer churn" returned the right answer? The finance analyst who asked it. Make them the teacher.
4. Embrace Ambiguity---Don't Hide It
When Netflix's system encounters a query like "Dark," it doesn't guess---it surfaces the ambiguity. This is uncomfortable for product teams who want magic, but it's honest. Users can clarify faster than they can recover from a confidently wrong answer.
5. Design for Augmentation, Not Replacement
Netflix explicitly aims to "augment and not replace existing applications." Their LLM layer works with their existing Graph Search infrastructure, not instead of it.
This matters for adoption. Analysts have existing workflows and tools they trust. An AI assistant that enhances those workflows will see adoption. One that demands wholesale replacement will face resistance.
The Bigger Picture: Why This Matters Now
The timing of Netflix's disclosure is notable. As of early 2025, virtually every major tech company is deploying LLM-powered data tools:
The enterprise data assistant market is rapidly maturing. But Netflix's LORE reminds us that the winning approach isn't about raw model capability---it's about building systems that earn and maintain user trust.
Dashboards proliferated because they were easy to build. They failed because they were hard to maintain and harder to trust. AI data assistants face the same risk: easy to demo, hard to deploy successfully.
Netflix's answer---explainability, confidence scores, user-driven fine-tuning, and semantic layer integration---points toward what enterprise AI data tools need to become: not oracles, but trusted collaborators.
---
The Netflix Technology Blog's multi-part series on Analytics Engineering work provides additional technical depth on DataJunction, real-time analytics guidance, and their broader data culture. Their Graph Search technical post offers detailed implementation guidance for RAG-based query generation.
Sources
---
If this excites you, we'd love to hear from you. Get in touch.
Rick Radewagen
Rick is a co-founder of Dot, on a mission to make data accessible to everyone. When he's not building AI-powered analytics, you'll find him obsessing over well-arranged pixels and surprising himself by learning new languages.